MySQL总结
mysql架构
连接/线程处理器->[查询缓存->解析器->优化器](服务器层)->储存引擎
mysql有一个线程池,每个连接的查询只会在一个单独的线程里处理。
对于select语句,在解析语句之前,会检查缓存,缓存有就直接返回。
并发控制
mysql使用读写锁进行并发控制,读锁共享,写锁独占。
并且将锁的颗粒度分为表锁和行锁,由储存引擎实现。
Innodb会检测并回滚持有最少的行级排它锁的事务。
在Innodb中,多版本并发控制(MVCC)只在读已提交和可重复读两个隔离级别下运行。
原理通过增加两个隐藏列,分别表示创建的事务版本号和删除的事务版本号。
每一个事务都有一个版本号,版本号自动递增,例如在可重复读中:
+ select:创建版本号小于当前,删除版本号为空或者大于当前
+ insert:创建版本号设置为当前
+ delete:删除版本号设置为当前
+ update:插入一条新的记录和创建版本号,设置旧的记录的删除版本号
事务特性(ACID)与隔离级别
原子性(atomicity):事务内的操作要不全部成功,要不全部失败
一致性(consistency):无论事务成功与否,前后的数据都要保持一致性,不能无端的多了少了
隔离性(isolation):在事务完成之前,其他事务对此不可见
持久性(durability):一旦事务成功,哪怕数据库奔溃,修改的数据也不会丢失
读未提交:脏读
读已提交:不可重复读
可重复读(Innodb默认)
- 幻读:如果事务查询
10<age<20的数量,别的事务新增一行age=15,回头再查10<age<20会发现数量+1 - Innodb会通过Next-Key Lock(间隙锁(GAP Lock)+行锁(Record
Lock))来锁定
10<age<20这个范围,阻塞新增的age=15。所以在Innodb下的可重复读并不会出现幻读
- 幻读:如果事务查询
串行化
B+树
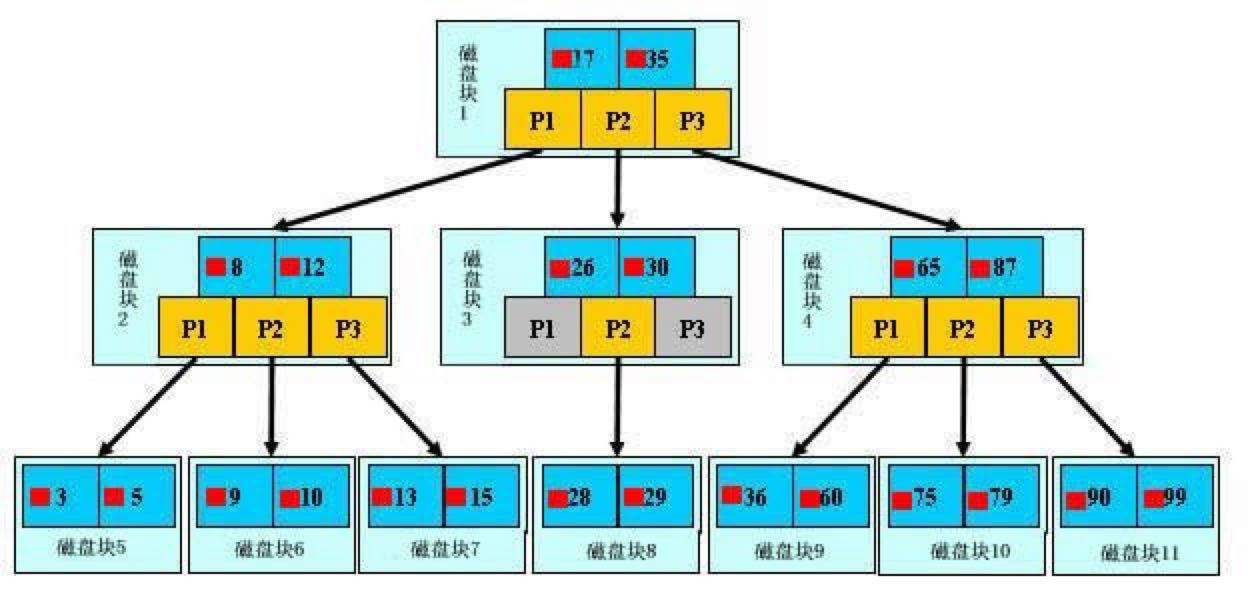
B+树是多叉树,每一个节点对应一块磁盘块,包含着大量的子节点的磁盘块指针。
每一次查找读取一块磁盘块,通过二分法查找子节点,直到叶子节点,查询到具体数据的指针。
具体数据的指针都在叶子节点里,非叶子节点不保存具体数据的指针,增加非叶子节点的子节点数量。使得B+树能更加矮,减少IO次数。
- 索引字段尽量要小,增加非叶子节点的子节点数量
- 对于联合索引,B+树会按联合索引的字段顺序构建树
- 尽量选择辨识度高(包含虽然值少但偏差大的)的字段做索引并排在联合索引的前面
- 尽量拓展现有索引,而不是新建索引
最左匹配原则
- 联合索引的where必须从左到右连续。但=和in可以乱序,mysql会帮忙调整顺序
- like的通配符%不出现在开头
- 范围查询(>、<、between、like)可以用到索引,但是范围列后面的列无法用到索引
- 查询条件中不得含有函数或表达式
explain字段含义
1 | |
- id:查询序号,数字越大越先执行
- select_type:查询类型
- SIMPLE:简单SELECT(不使用UNION或子查询)
- PRIMARY:最外层的SELECT
- UNION:UNION中第二个或之后的SELECT语句
- DEPENDENT UNION:UNION中第二个或之后的SELECT语句,取决于外面的查询
- UNION RESULT:UNION的结果
- SUBQUERY:子查询中的第一个SELECT
- DEPENDENT SUBQUERY:子查询中的第一个SELECT, 取决于外面的查询
- DERIVED:衍生表(FROM子句中的子查询)
- MATERIALIZED:物化子查询
- UNCACHEABLE SUBQUERY:结果集无法缓存的子查询,必须重新评估外部查询的每一行
- UNCACHEABLE UNION:UNION中第二个或之后的SELECT,属于无法缓存的子查询
- table:表名
- partitions:匹配的分区
- type:查询方式,从好到坏
- system:只有一行数据或者是空表,且只能用于MyISAM和memory表,Innodb在这个情况通常都是all或者index
- const:最多只有一行记录匹配,唯一索引等于常量值时
- eq_ref:最多只有一行记录匹配,唯一索引等于非常量值时
- ref:用到索引但不是唯一索引
- fulltext:全文索引
- ref_or_null:在ref基础上加了NULL的比较
- index_merge:查询使用了两个或以上索引,常见and or使用了不同索引,最后取交并集
- unique_subquery:
where in (子查询),子查询返回不重复值唯一值 - index_subquery:类似于unique_subquery。适用于非唯一索引,可以返回重复值
- range:索引范围查询
- index:通过索引扫描全表。如果是索引覆盖,Extra会有Using index。否则回表的话没有Using index
- all:全表扫描
- prossible_keys:可能会选择的索引
- key:实际选择的索引
- key_len:索引的长度。单索引则是索引长度,联合索引则是用到多少个字段算多长
- ref:与索引作比较的列
- rows:要检索的行数(估算值)
- filtered:查询条件过滤的行数的百分比
- Extra:额外信息
- distinct:select使用了distinct关键字
- Using filesort:表示不能通过索引进行排序,需另外排序
- Using index:索引覆盖
- Using temporary:使用了零时表,一般出现于排序, 分组和多表join
读写分离
- 主库将修改写入binlog文件
- 从库连接到主库,会起一个IO线程把binlog复制到自己的中继日志中
- 然后再起一个SQL线程从中继日志中读取执行binlog的的命令
- 一般延迟几十或几百毫秒,如果此时主库挂了,数据就丢失了
- 半同步复制:主库写入binlog之后强制数据立即同步到从库,至少有一个从库确认同步了才算写入成功
- 并行复制:起多个SQL线程来执行中继日志
分库分表
一个表控制在两百万以内,一个库最好一千QPS,最多两千QPS。
+ 水平拆分:同样的表结构拆分到多个库里
+ 垂直拆分:把字段拆分到多个表里,将高频字段与低频字段拆到不同表里
分库分表路由:
+
每个库都是连续的数据。但对于时间分段就可能都访问最新的热数据,负载不均匀
+ 用某个字段来hash,不过扩容要做数据迁移
分库分表过度:
+ 双写->导数据(检查版本号)
分库分表主键:
+ 主键id自增步长
+ redis自增
优化
- 表设计优化
- 使用整型表示枚举字符串
- 尽量不使用null,索引里null被认为是最小值,会被放在最左边,如果有大量null会降低索引性能
- 尽量别
select *,尽量count(*) - 货币数据使用decimal
- 索引优化:如上
- 读写分离:如上
- 分库分表:如上
InnoDB与MyISAM
InnoDB是聚集索引,即索引跟数据在一起。必须有主键(没有会自建一个隐藏的),非主键->二级索引->主键->一级索引->数据。
而MyISAM的索引则是保存数据文件的指针。
| InnoDB | MyISAM | |
|---|---|---|
| 存储结构 | 索引和数据都保存在一个文件里 | 分为表结构、索引和数据三个文件 |
| 事务 | 支持 | 不支持 |
| 全文索引 | 不支持 | 支持 |
| 锁 | 表锁和行锁 | 表锁 |
| CURD | 偏向于写 | 偏向于读 |
| 数据恢复 | 相对容易 | 相对困难 |
Binlog
Binlog会记录每一个更新操作,作为一个事件。在记录模式上分为三类:
+ statement:记录所执行的SQL
+ row:记录每一行数据的变化字段的前后值
+ mixed:statement和row的混合模式
使用场景:
+ 读写分离:主从同步
+ 数据恢复
+
数据同步:binlog->MQ-其他服务(redis、ES)。使用binlog同步组件拉取。
+ 异地多活:主键冲突、数据回环问题
参考文章:
MySQL InnoDB中的行锁 Next-Key Lock消除幻读