Redis总结
缓存作用
- 高性能:查询速度快
- 高并发:支持并发高
Redis模型
- 先注册server socket的可读事件。
- 当有客户端请求接入,IO多路复用就会把server socket放进队列里。
- 然后事件分派器会把server socket分派到应答处理器里,获得与客户端连接的socket,将socket的可读事件与命令请求处理器关联。
- 当客户端发出命令请求,socket有可读事件,事件分派器就会把socket分派到命令请求处理器。
- 执行命令完成后,会把socket的可写事件与命令回复处理器关联。
- 等到客户端可写,有可写事件,又会把socket放进队列里,分派到命令回复处理器回复命令执行结果。
- 使用纯内存,速度快
- 使用IO多路复用
- 命令执行为单线程,避免上写文切换
redis的单线程只是命令执行使用单线程,处理网络IO和后台删除过期key是使用多线程处理的。
redis一开始使用单线程处理是因为IO多路复用,加上操作都是纯内存操作,处理速度快,单个线程就可以处理大量的连接。
但是其中有很多的cpu时间是用来进行网络IO的,所以把网络IO和其他后台任务用多线程提高处理速度,命令执行依然用单线程。
Redis数据类型与使用场景
- string
- 分布式锁
- 自增计数器、秒杀、访问频率
- 分布式唯一ID:时间戳+自增值
- list
- 消息队列:往左边加数据
lpush key value。往右边取数据,没有数据则阻塞到超时(如10s)brpop key value 10 - 列表最新消息:消息从左边插入,查左边前十个消息
lrange key 0 9
- 消息队列:往左边加数据
- hash
- set
- 抽奖活动:所有抽奖用户
smembers key,随机抽N个用户并删除spop key N,随机抽N个用户不删除srandmember key N - 点赞、签到、like功能
- 共同关注、可能认识的人:交并差集
- 抽奖活动:所有抽奖用户
- sorted set
- 排行榜
string
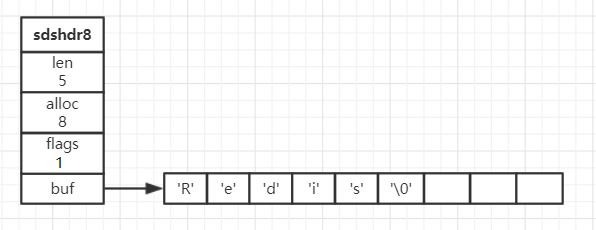
redis的字符串没有使用c自带的字符串,而是重新实现了一个简单动态字符串(simple
dynamic string,SDS)。
但SDS除了扩容还会惰性缩容,缩容后会把空间腾出来,以备以后扩容,并不会重新分配内存。
扩容规则是小于1M则比len*2大的2^n,大于1M的则len+1M。
有点像StringBuilder,StringBuilder内部也有个char[]可以扩容追加内容。
+
buf:二进制数组,保存数据,休止符为'\0'
+ len:字符串长度
+ alloc:标头和休止符的长度
+ flags:字节属性,是sdshdr8还是sdshdr16
list
redis的链表就是个标准的双向链表,list对象有头尾节点和节点数量
hash
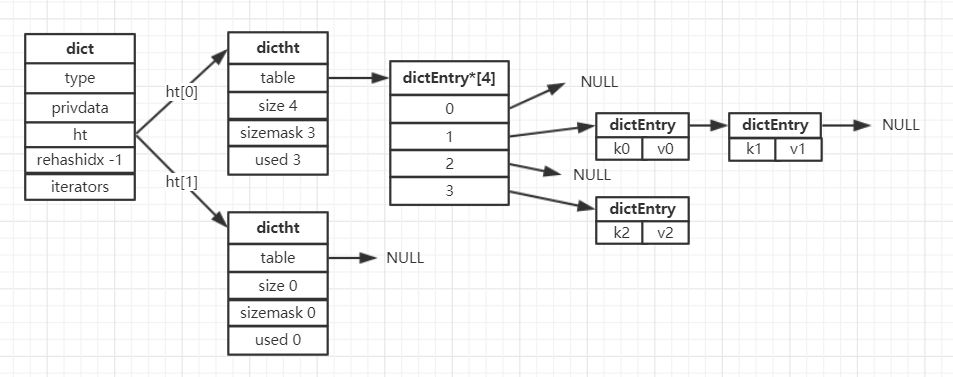
redis的hash也与java的类似,hash桶的个数是2^n,每个桶里是个链表。
但实际hash桶的数组有两个,在ht这个数组里。
ht[0]和ht[1]是一样的,不过ht[1]是在rehash的时候使用。
扩容rehash条件是负载因子(ht[0].used / ht[0].size)大于1,缩容rehash条件是负载因子小于0.1。
扩容是创建一个大于ht[0].used*2的2^n大小的ht[1]。
缩容则是创建一个大于ht[0].used的2^n大小的ht[1]。
将ht[0]的数据rehash到ht[1]里,完成后将ht[1]改为ht[0],ht[1]改置空。
并且避免数据量大时rehash导致卡顿。所以会使用渐进式rehash。
也就是会初始化一个新的ht[1],在每次增删查改的时候,把ht[0]rehash到ht[1],把rehashidx+1。
set
redis的set在数据量不大的时候会时候整数集合(intset)的结构,如果数据量大的话,则使用hash来保存。
intset包含三个字段,分别是
+ contents[]:正数数组,从小到大排序,不重复
+ length:元素数量
+ encoding:编码方式
sorted set
sorted
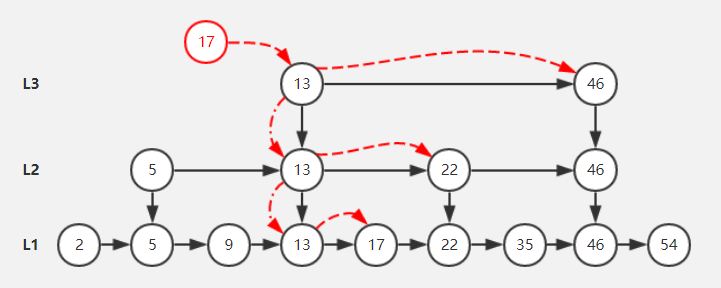
set的底层结构是跳跃表。跳跃表其实就是多层的链表,每一次链表都是有序的。
底层链表包含着全部的节点,新增节点时,首先节点肯定是在底层链表里的。
然后这个节点有50%的机会向上一层,所以一二三层节点的概率为0.5,0.25,0.125……。
查找是从上层链表查起,比较大小之后逐层往下,知道找到或者在底层也找不到数据为止。
查找、增删的时间复杂度是logN。
由于是随机定节点所在的层,所以跳跃表只是大致均匀,不同于普通二叉树的不均匀和红黑树的严格均匀。
Redis过期策略
- 定期删除:每隔一段时间随机抽一些key看看过期了没,过期了清掉
- 惰性删除:当某个key被查询到,先检查这个key过期了没,过期了清掉,返回空
- 定时删除:每个key设置一个定时器,时间到了就删除此key
定期删除+惰性删除,但是会导致大量过期key积累,耗尽内存
缓存淘汰策略
- noeviction: 写入新数据就报错
- allkeys-lru:删除最少使用key(最常使用,可以简单用LinkedHashMap实现)
- allkeys-random:删除随机key
- volatile-lru:删除有过期时间的最少使用key
- volatile-random:删除有过期时间的随机key
- volatile-ttl:删除最快过期的key
缓存淘汰算法(LRU、LFU)
LRU:如果数据在列表里,则把数据移到顶部。如果不在则弹出底部数据,插入新数据。
java里可以用LinkedHashMap简单实现,用remove来get,之后put回去。但是没相应的api删除底部数据。
也可以map+双向链表实现。链表用于增删数据。map用于查找,key-链表节点。
map可以参考ThreadLocal用弱引用,或者能通过链表节点获取key。
redis的LRU,对象维护一个24位的时间戳作为最后活跃时间。
当要清理数据时,会随机拿出N个对象(默认五个),删除活跃时间最久远的那个。
但是活跃最久远不等于最不活跃,所以LFU改造了时间戳,前16位表示时间,后八位表示活跃频率。
LFU会根据时间长短和活跃频率来权衡活跃程度。为了避免删除新键,可以对新键设置默认活跃频率。

Redis持久化
RDB
fork一个子进程进行RDB持久化,不用线程是避免锁竞争
父进程和子进程共享内存,操作系统会对内存进行分页
当父进程需要修改数据时,会把相应的内存页复制一份,子进程看到的内存依然是不变的
RDB可以设置多久之内有多少个数据发送改变就触发持久化
备份间隔长,丢的数据比较多
对性能影响小,适合做冷备份
重启恢复速度比AOP快
## AOF所以写命令会写入aof缓存,子进程根据策略追加到文件里(例如每秒)
当AOF文件过大,进行重写压缩的时候会生成新的文件,旧的文件照常写入
一般是RDB和AOF两种都同时开启,这样既能RDB的快速恢复,也有AOF的少丢数据
Redis主从架构
对于缓存一般都是支持读高并发,所以使用一主多从,写在主节点,读在从节点。主节点必须开启持久化。
当从节点初次连接到主节点,会触发一次全量复制
主节点会起一个线程生产一个RDB快照,同时将接受到的写命令缓存到内存里
主节点会把RDB快照发给从节点,从节点会把RDB文件保存到硬盘里
从节点会清空自己的数据,加载RDB数据到内存里。期间以旧数据对外提供服务
如果因为RDB文件过大等原因,导致复制时间超时(默认60s)会认为复制失败
主节点会把内存里缓存的写命令发给从节点
主节点会在内存里维护一个backlog,以及主从节点都会保存一个replica offset
如果主从网络断开,恢复时会从上次的replica offset里继续复制数据
如果找不到对应的replica offset,则会触发一次全量复制
Redis哨兵集群
- 集群监控:负责监控集群的节点是否正常
- 每隔1s对节点发ping心跳检测,如果超时时间内没有回应,则为主观下线
- 询问其他哨兵节点此节点的状态,如果超半数都主观下线,则为客观下线
- 故障转移:如果主节点挂了,会转移到从节点上
- 哨兵集群选出领导者
- 剔除下线和未主从同步时间过长的从节点
- 同步偏移量最大->运行ID最小,选择新的主节点
- 消息通知:将新主节点信息通知客户端
- 配置中心:客户端可在哨兵节点获取主节点信息
哨兵集群选举
- 每个发现主观下线的哨兵节点向其他哨兵节点发送命令,请求自己成为领导者
- 同意第一个请求,拒接其他请求
- 如果哨兵节点发现自己获得过半数票,则为领导者
- 如果有多个领导者,稍后再试
- 哨兵节点至少三个或以上(两个哨兵节点共同决策,如故障转移。所以最少要三个节点,保证哨兵集群的高可用)
哨兵集群的数据丢失
- 故障转移后,从节点没完整复制数据
- 主节点脱离了正常网络但还运行着,故障转移后就有两个主节点。
客户端可能还没来得及切换主节点,导致往旧主节点写数据。
当旧主节点网络恢复加入集群成为从节点,就会被清空数据
可以配置使主节点至少跟一个从节点的数据同步少于10s,大于就拒绝写操作
集群模式
使用
CRC16(key) & 16384将key分派到一万六千多个槽的其中一个槽的数量是固定的,集群的每一个主节点负责一部分的槽
客户端连接到集群的某个节点,如果key对应的槽在本节点就直接处理
否则会告知客户端槽所在节点的信息,让客户端再去自行请求
集群节点之间是网状结构,每个节点都会与其他节点保存连接,并且传播加入和离开的节点信息与槽信息
所以新加和删除节点,通过迁移槽和槽数据,迁移完成后刷新槽信息
如果某个节点ping另外的节点,在超时时间内都没有效响应,则为主观下线
节点会向其他节点询问,如果过半数节点都认为下线了,则为客观下线
从节点根据自己的同步偏移量设置参与选举时间。同步越全则选举越早
全部主节点给从节点投票,过半数者成为新的主节点
缓存雪崩
由于缓存被删除/过期/宕机导致请求都到了数据库里
+ 事前:高可用,主从哨兵或者Redis集群
+ 事中:使用本地缓存、服务限流降级,避免数据库被打死
+ 事后:使用RDB/AOF重启恢复redis数据
缓存穿透
编造大量不正常数据,无缓存,导致都打到数据库
+ 检查数据合法性
+ 将这些数据也缓存到Redis里
缓存击穿
热点数据过期,大量请求打到数据库
+ 基本不跟新,考虑将数据设置为不过期
+ 用Redis锁进行更新
+ 起一个定时任务主动更新
缓存与数据库的一致性
先更新数据库再删除缓存,缓存lazy生成
如何保证缓存与数据库双写一致性?里说的:
先更新数据库,再删除缓存。如果删除缓存失败了,那么会导致数据库中是新数据,缓存中是旧数据,数据就出现了不一致。
解决思路:先删除缓存,再更新数据库。如果数据库更新失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致。
因为读的时候缓存没有,所以去读了数据库中的旧数据,然后更新到缓存中。
我觉得是无稽之谈,缓存数据不是一般都有过期时间吗,过期兜底不就好了吗?
为什么redis删数据失败,读数据还能成功?这时候是不是应该考虑一下是不是redis挂了?
先删了缓存,还没改数据库的数据又被其他请求查回缓存里了,不也一样导致不一致吗?
参考文章: