拖沓下来的各种笔试笔记
hashcode与equals
这两个方法在Object类里已经有。hashcode用于获取对象的hash值,而equals用于判断对象是否一样。在Object里,hashcode是个本地方法,返回这个对象存储的内存地址的编号。而equals是用==来判断的。所以,在Object里,无论是hashcode还是equals,只有同一个对象才会相等。
当然这种同一个对象才会相等的是不一定符合实际的,new两个内容一样的String,==比较不一样,但equals是相等。所以我们有时候是需要根据实际情况去重写equals方法。但是一般hashcode方法与equals方法是需要同时被重写的,因为这两个方法有一下关系:
- equals相等的两个对象hashcode一定相等
- hashcode相等的两个对象,equals不一定相等
导致这种情况的原因是,equals方法的判断逻辑可以由我们自己控制,其判断的结果也是可预测正确的。但是hashcode有可能发生hash冲突,而这种冲突是难以避免的。因此equals的判断比hashcode要严格。
虽然equals和hashcode有这种关系,但是如果我只调用我重写的那个方法,另外那个不调用不就没问题了吗?话是这么说,但也只是自己的不调用,不代表别人的代码不调用呀,这两个Object继承下来的方法又没有办法禁止调用。
所以,要重写的话最好这两个方法一起重写。就例如java的HashMap,HashSet这些用到hash的类,一般都会两个方法都调用。Map的key是唯一的,Set的元素是唯一的。如果用遍历的方法效率太低,因此在HashMap和HashSet里是使用hash的方法来快速定位的,这里例如插入:
- 先用计算hashcode来计算索引,查找到相应的桶
- 如果桶内的元素的hashcode没有一个跟要被插入的元素一样的话,那肯定没有一个元素跟要被插入的元素一样,可以插入了。
- 如果某个元素的hashcode跟被插入的元素一样,由于hash冲突的缘故,只能认为有很大可能性这连个元素是一样的,所以需要再用equals来判断。
这里先使用hashcode再使用equals,而不是直接使用equals是为了性能考虑,据网上的文章说,hashcode的效率会比equals高。
HashMap,HashTable,ConcurrentHashMap与null
HashMap的key和value都可以为null
HashTable,ConcurrentHashMap的key和value都不可以为null
redis
redis是个key-value的Nosql数据库。
- 相比于memcached只支持字符串,redis支持string,list,set,sorted set,hash
- 相比于memcached断电后会挂掉,redis支持数据持久化
- 相比于memcached的value支持最大1M,redis的value支持最大1G
- redis将全部数据放进内存,读写效率更高
- redis通过队列将并发的操作串行
- redis支持事务,操作都是原子性的
redis的一些使用场景:会话缓存(Session Cache),全页缓存(FPC),队列,排行榜/计数器,发布/订阅
awk与sed
awk和sed都可以用来查看文本,特别的大文本的搜索。
awk的简单使用。awk是一行一行读取处理的,默认使用空格或者tab作为分隔符分割每一行。全部列用$0表示,第n列用$n表示。-F用于指定分隔符。root为正则表达式用/括起来。print $7指的是打印第七列。所以下面命令含义是:对/etc/passwd文件的每一行以:分割,正则匹配有root的行,并且把这些行的第七列打印出来。
1
awk -F ":" '/root/{print $7}' /etc/passwd
sed的简单使用。sed跟awk一样也是一行一行读取处理的。
1
2
3
4
5
6
7
8
9sed [-nefr] [动作]
#删除第2-5行,其余打印出来
cat /etc/passwd | sed '2,5d'
#打印出正则匹配到root的行
cat /etc/passwd | sed -n '/root/p'
#不打印正则匹配到root的行
cat /etc/passwd | sed '/root/d'
#正则匹配root的行,然后把bash替换成blueshell,然后打印
cat /etc/passwd | sed -n '/root/{s/bash/blueshell/;p}'
- -n:只将sed操作过的行打印出来,否则打印全部内容
- -f:将内容输出到文件里:-f filename
- -i:直接修改文件内容(危险动作)
ThreadLocal
ThreadLocal可以使用在某个变量我们希望他是静态的,非终态需要被修改的。但是如果在多线程下,没有任何的同步,修改这个变量将可能会有安全问题。这时候就可以用到ThreadLocal了。我们可以创建一个静态ThreadLocal对象,各个线程都可以获取到同一个ThreadLocal对象,但是ThreadLocal对象里的值的读取与修改是线程隔离的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public class ThreadLocalTest extends Thread {
public static final ThreadLocal<Double> THREAD_LOCAL = new ThreadLocal<Double>();
public static void main(String[] args) {
ThreadLocalTest t1 = new ThreadLocalTest("线程1");
ThreadLocalTest t2 = new ThreadLocalTest("线程2");
t1.start();
t2.start();
}
public ThreadLocalTest(String name) {
super(name);
}
@Override
public void run() {
for (int i = 0; i < 3; i++) {
try {
Thread.sleep((int) (1000 * Math.random()));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.print(Thread.currentThread().getName() + "拥有对象:" + THREAD_LOCAL.hashCode());
System.out.print(",将原值:" + THREAD_LOCAL.get());
THREAD_LOCAL.set(Math.random());
System.out.println(",修改为:" + THREAD_LOCAL.get());
}
}
}
可以看到各个线程的ThreadLocal对象的hashcode是一样的,两个线程之间对ThreadLocal的修改也是隔离的。
1
2
3
4
5
6线程2拥有对象:2095837363,将原值:null,修改为:0.705228440823234
线程1拥有对象:2095837363,将原值:null,修改为:0.5296305103135809
线程2拥有对象:2095837363,将原值:0.705228440823234,修改为:0.04926391538070962
线程1拥有对象:2095837363,将原值:0.5296305103135809,修改为:0.6740029732678001
线程1拥有对象:2095837363,将原值:0.6740029732678001,修改为:0.08663362271690767
线程2拥有对象:2095837363,将原值:0.04926391538070962,修改为:0.9500871116032077
线程创建的三种方法
- 继承Thread类
- 实现Runable接口,new Thread时传入Runable对象
- 实现Callable接口,new FutureTask是传入Callable对象。FutureTask实现了Runable和Future接口,所以new Thread时传入FutureTask对象
1 | |
mysql的几种索引
- 普通索引:没有任何要求
- 唯一索引:要求索引的列的值是唯一的
- 主键索引:是个特别的唯一索引,并且要求不为null
- 全文索引:仅可用于MyISAM,针对较大的数据,生成全文索引很耗时好空间。
- 联合索引:遵循最左匹配原则
jdk8的新特性
接口
1 | |
lambda表达式和函数式接口
lambda表达式本质是一种匿名内部类,形式是:(参数列表) -> {语句块}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21//例如一个方法
public String sayHi(String name){
System.out.println("hello:"+name);
return "hello:"+name;
}
//lambda表达式
(String name) -> {
System.out.println("hello:"+name);
return "hello:"+name;
}
//或者省略入参类型,jvm会自动判断
(name) -> {
System.out.println("hello:"+name);
return "hello:"+name;
}
//以及
new Thread(() -> {
for (int i = 0; i < 3; i++)
System.out.println("use lambda is :"+i);
}
}).start();
内部类
1 | |
#java的容器类
先盗图贴个。上面的是简单版,下面的是完整版
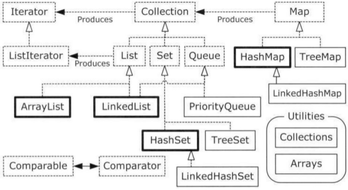
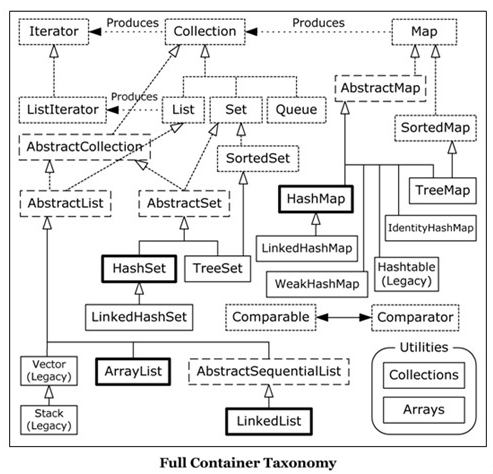
## 容器接口
1. Collection
1
2
3
4
5
6
7boolean add(Object obj)
Iterator iterator()
int size()
boolean isEmpty()
boolean contains(Object obj)
void clear()
<T> T[] toArray(T[] a)
2. Map
1
2
3
4
5
6
7Object get(Object key)
Object put(Object key, Object value)
Set keySet()
Set entrySet()
Set<Map.Entry<K,V>> entrySet()
containsKey()
containsValue()
3. Iterator
1
2
3Object next()
boolean hasNext()
void remove()
子接口
- List
1
2
3
4boolean add(E element)
void add(int index, E element)
E set(int index, E element)
E get(int index); - Set
抽象容器类
略过
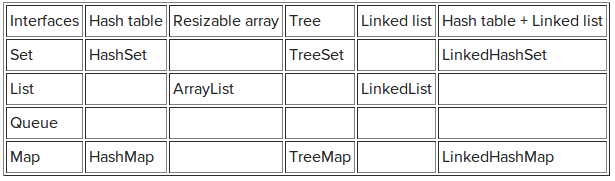
## 实现类
1. List:ArrayList, LinkedLsit, Vector, Stack
2. Set:TreeSet, HashSet, LinkedHashSet
3. Map:HashMap, LinkedHashMap, WeakHashMap, TreeMap, HashTable
Vector为同步的ArrayList,效率比ArrayList低。Stack继承Vector,为后进先出的堆栈。HashSet为无序set,TreeSet为以一定规则排序的set,LinkedHashSet为以添加顺序的set,Map同理。
spring的单例与多例
spring的bean对象默认是单例,如果想多例
1
2
3
4
5//默认单例
@Component
//设置多例
@Component
@Scope("prototype")
参考文献:
Java提高篇——equals()与hashCode()方法详解
Java进阶(七)正确理解Thread Local的原理与适用场景