Linux的IO模型
本文主要是聊聊 Linux 中的五种 IO 模型的概括。
对于32位的计算机,操作系统最多给每个进程分配4G的内存。针对linux而言,linux会把其中1G分配为内核空间,另外3G分配为用户空间。
- 阻塞:进程被迫等待内核
- 非阻塞:进程可以不等待内核
- 同步:进程向内核发起调用
- 异步:内核向进程发起调用
内核会先将数据写到内核空间的缓冲区里,之后内核才会将数据从内核空间拷贝到用户空间里,进程才能读取数据。所以进程有两个等待阶段。
1. 阶段一:等待数据从硬件写入内核空间(准备数据)
2. 阶段二:等待数据从内核空间写入到用户空间(拷贝数据)
| 同步 | 异步 | |
|---|---|---|
| 阻塞 | 同步阻塞IO,多路复用IO | |
| 非阻塞 | 同步非阻塞IO | 异步非阻塞IO |
| 阶段一 | 阶段二 | |
|---|---|---|
| 同步阻塞IO | 阻塞 | 阻塞 |
| 同步非阻塞IO | 非阻塞,轮询 | 阻塞 |
| 多路复用IO | 阻塞 | 阻塞 |
| 异步非阻塞IO | 非阻塞,异步等回调 | 非阻塞,异步等回调 |
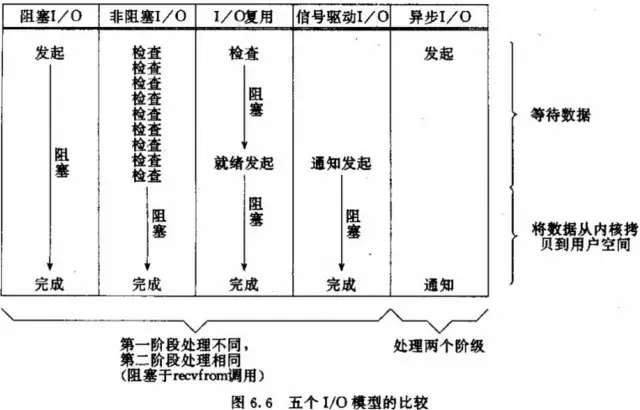
同步阻塞IO(BIO)
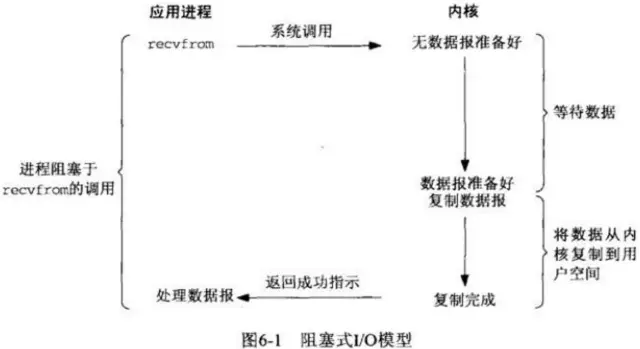
阻塞IO,进程发起read操作被阻塞,此时内核会开始准备数据,数据准备好了,再将数据从内核空间写入到用户空间,然后read操作才返回,进程解除阻塞状态。
显然,这样子进程的大部分时间都在阻塞等待数据的准备和拷贝。
同步非阻塞IO(NIO)
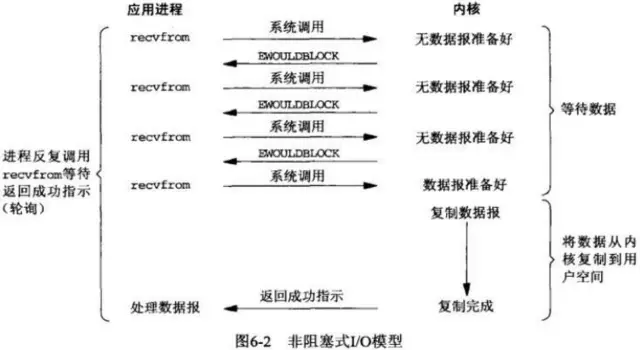
非阻塞IO,进程发起read操作,内核会立即返回,如果数据还没准备好,会返回一个error。
进程得到error的结果后,可以去做其他事情,待会再来轮询read操作,再次查询准备结果。
如果数据准备好了,进程又发起read操作,进程将会被阻塞,直到数据从内核空间写入到用户空间。
非阻塞IO问题在于绝大部分的轮询调用是无效的,消耗CPU时间。
多路复用IO
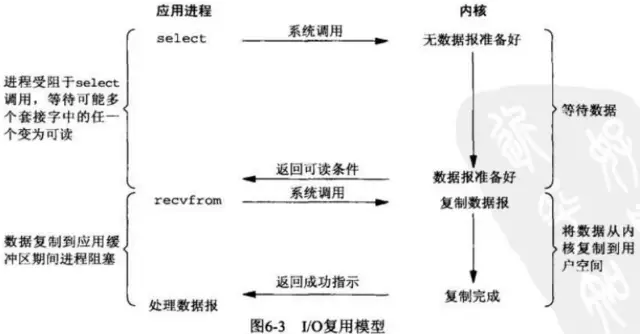
UNIX/Linux提供了select、poll、epoll系统调用(epoll比poll、select效率高,做的事情是一样的)。
进程发起select调用,进程会被select调用阻塞,然后内核会监视这个select所负责的NIO的数据准备情况。
如果有一个数据准备好了,select就会返回。然后进程再去发起read操作,被read操作阻塞,直到数据从内核空间写入到用户空间。
所以多路复用就是多路NIO复用一个进程进行处理,因此一个进程就能处理多个NIO,提高并发量。
当连接数不是很高,使用多路复用性能和响应速度可能会被BIO要差。
虽然多路复用使用的是NIO,但是由于进程在阶段一被select调用阻塞(虽然不是被IO阻塞),阶段二被read操作阻塞,所以对于进程而已,多路复用IO还是BIO。
异步非阻塞IO(AIO)
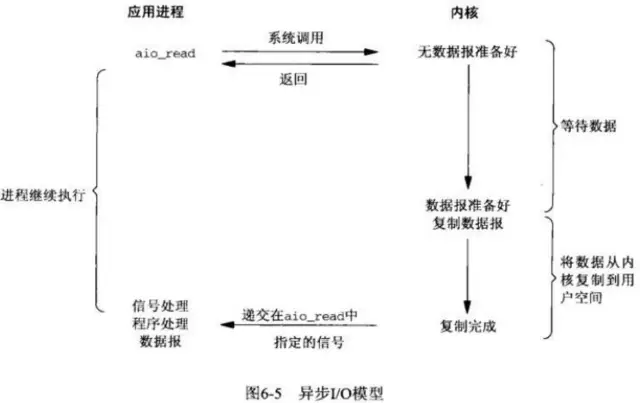
进程调用aio_read操作,内核空间无论是否已经准备好数据没有,内核都会立即返回,进程就可以去做别的事。
之后内核会负责将数据缓存到内核空间,然后将数据从内核空间写入到用户空间。
在阶段一和阶段二完成后,内核才会去通知进程。
关于异步阻塞
像js里,有时候虽然调用时异步的,但为了避免层层的callback嵌套,希望能阻塞到完成,这时候需要异步阻塞。
总结
select
调用select会把相应socket的fd_set从用户空间拷贝到内核空间,阻塞直到有就绪事件或者超时返回。
调用返回会把fd_set从内核空间拷贝回用户空间。之后遍历整个fd_set,来找就绪的socket。
select几乎在所以平台都支持,但是在linux上限制了单进程fd最大为1024,并且需要通过轮询遍历来查找就绪socket,效率低。
poll
poll基本跟select一样,但是他使用链表保存fd_set,所以没有fd数量限制。
但是依然存在来回的拷贝和遍历socket问题。
epoll
epoll的fd限制于硬件资源,1G内存机器能打开十万连接。
只有活跃的socket才会调用回调函数,并且通过内存映射共享内存,减少数据拷贝。
epoll对fd的操作模式有两种,水平触发(level trigger,LT)和边缘触发(edge
trigger,ET)
+
水平触发:内核会通知某个socket就绪,如果不做任何操作的话,内核还会继续通知
+
边缘触发:内核之后通知一次就绪事件,如果不做任何操作的话,内核下次就不再通知了
参考文章: