临急抱佛脚之HashMap源码
先上图吧,图说的最清楚,侵删。HashMap的组成单位是Node,Node储存这key-value。最普通的hash存储法,用对象的hashCode方法算出hash,hash对数组长度求余便是这个对象的索引。但是这样会导致hash冲突,所以当hash冲突时,通过链表来解决。但是,如果这个不巧,大部分的key都冲突在一起,那么就会HashMap退化成链表。所以在java8之后,当链表太长时,会把链表装换成红黑树来提高查找效率。如图,左边那一列的Node数组,这个数组名字叫table,上面的是链表,中间的是红黑树。table数组的每一个元素及其链表/红黑树叫桶。
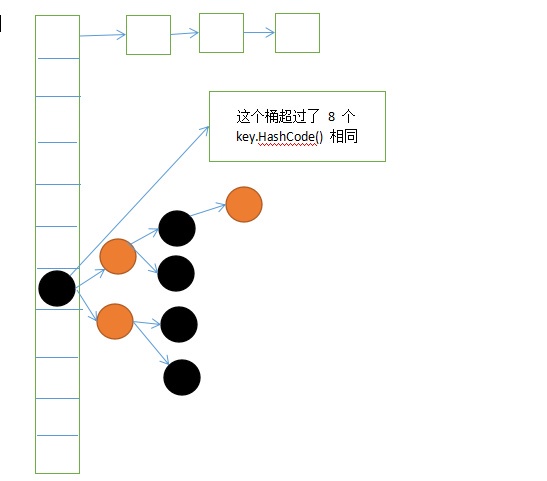
因此对于某一个桶,不断添加节点的过程如下:
为空,没有数据
只有一个数据,没有hash冲突
有2-8个,处于链表状态
是一棵9-多个节点的红黑树
HashMap的hash函数
HashMap的hash并不是简单通过key的hashCode求余了事。HashMap会根据key的hashCode在进行计算才得到hash值。
1
2
3
4
5
6
7
8
9/**
* 计算key的hash
* @param key
* @return
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
HashMap的节点
这里当链表的节点超过8个的时候,就会转换成红黑树,当红黑树的节点不断被删除,少于6个的时候,就会变成链表。这里有链表和红黑树两种数据结构,所以也有两种节点。链表的节点HashMap.Node<K,V>,除了存储的key-value外,还有链表所需的next节点,实现Map.Entry<K, V>接口。而红黑树的节点继承于LinkedHashMap.Entry<K,V>,LinkedHashMap.Entry<K,V>继承于HashMap.Node<K,V>。所以为红黑树的节点是链表节点的孙子类。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 /**
* 链表的节点,实现Map.Entry<K, V>接口,可以当Map.Entry<K, V>返回
* 有hash,key,value,next
* @param <K>
* @param <V>
*/
static class Node<K, V> implements Map.Entry<K, V> {
final int hash;
final K key;
V value;
HashMapCode.Node<K, V> next;
Node(int hash, K key, V value, HashMapCode.Node<K, V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
//。。。
}
static final class TreeNode<K, V> extends LinkedHashMap.Entry<K, V> {
HashMap.TreeNode<K, V> parent; // red-black tree links
HashMap.TreeNode<K, V> left;
HashMap.TreeNode<K, V> right;
HashMap.TreeNode<K, V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, HashMap.Node<K, V> next) {
super(hash, key, val, next);
}
//。。。
}
HashMap的get方法
HashMap的源代码我只看了个开头,但是我发现了些套路。如上所说,某个桶可能有四种状态,在get和put方法里都是通过if语句来判断,围绕这四种状态进行操作的。例如比较简短的get方法。下文代码注释中所谓的索引处,索引下其实就是桶,懒得改了
1 | |
HashMap的容量参数
HashMap的table是个数组,自然就要考虑扩展的问题。这里先介绍HashMap的关于大小的一些变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22//默认table长度为2^4=16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//最大容量,即最多容纳多少个Node,2^30
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认负载,0.75,当节点数大于table的长度*这个负荷,将需要扩展
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//链表变红黑树的节点数阈值
static final int TREEIFY_THRESHOLD = 8;
//红黑树变链表的节点数阈值
static final int UNTREEIFY_THRESHOLD = 6;
//如果table的长度大于64,才会考虑把大于8的链表转换成红黑树?
static final int MIN_TREEIFY_CAPACITY = 64;
//table的真面目,transient关键字是在序列化过程中,剔除不想被序列化的变量
transient HashMapCode.Node<K, V>[] table;
//所存储的Node数量
transient int size;
//HashMap 结构修改次数,防止在遍历时,有其他的线程在进行修改
transient int modCount;
//当size大于这个阈值时,将需要扩展。
int threshold;
//负荷
final float loadFactor;
HashMap的扩展函数
函数处理用来扩展table之外,还会用来初始化table。每次扩展table之后大小将翻2倍,并返回新的table。至于为什么是翻2倍而不是翻3倍,是为了保证table的长度始终是2的次方。这样在计算索引时,就不需要通过求余计算,只需要通过&位运算就能得到均匀的分布,计算方法为(n - 1) & hash,n是table长度。至于为什么我也不知道。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73/**
* 所以resize之后,空table会被初始化,非空table会翻倍
* @return
*/
final HashMapCode.Node<K, V>[] resize() {
HashMapCode.Node<K, V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {//普通情况下table有数据
if (oldCap >= MAXIMUM_CAPACITY) {//旧容量》最大容量,就直接返回旧table
threshold = Integer.MAX_VALUE;
return oldTab;
} else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)//没大于最大容量就把容量和阈值翻倍
newThr = oldThr << 1;
} else if (oldThr > 0)//旧阈值》0就赋值给新阈值,这个应该是对于构造函数传入的初始容量的处理,因为构造函数里并没有操作过容量,只是给阈值赋值了,解释了这里把旧阈值赋值给新容量的奇怪
newCap = oldThr;
else {//本来table就是空的,用来初始化table
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int) (DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float) newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float) MAXIMUM_CAPACITY ? (int) ft : Integer.MAX_VALUE);
}
threshold = newThr;
//创建新tbale
@SuppressWarnings({"rawtypes", "unchecked"})
HashMapCode.Node<K, V>[] newTab = (HashMapCode.Node<K, V>[]) new HashMapCode.Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {//把旧table值转移到新table
HashMapCode.Node<K, V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)//索引下已有一个节点
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof HashMapCode.TreeNode)//如果是树就放到树里?
((HashMapCode.TreeNode<K, V>) e).split(this, newTab, j, oldCap);
else {//最后这个应该就是链表了
HashMapCode.Node<K, V> loHead = null, loTail = null;
HashMapCode.Node<K, V> hiHead = null, hiTail = null;
HashMapCode.Node<K, V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
} else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap的put方法
1 | |
HashMap的链表变红黑树方法
1 | |
HashMap的阈值
1 | |
HashMap的构造方法
最后是HashMap的构造方法。我们可以看到构造方法并没有对table进行初始化,table的初始化都是交给resize方法的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25/**
* 输入初始容量与负荷
* 检查0《容量《最大容量,负荷是数字 && 0《负荷
* 计算容量阈值并赋值,赋值负荷
* @param initialCapacity
* @param loadFactor
*/
public HashMapCode(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMapCode(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMapCode() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
HashMap的remove方法没看,但是相信也是围绕四种状态来进行操作的。
参考文献