再看ConcurrentHashMap源码(1.7与1.8)
之前我写的临急抱佛脚之ConcurrentHashMap源码是java7的实现。面试的时候被问到ConcurrentHashMap在java7和java8的实现上有什么区别,我就只知道个会链表变红黑树。至于java8中新的并发机制却没有了解。为此补这篇文章。
Java7的ConcurrentHashMap
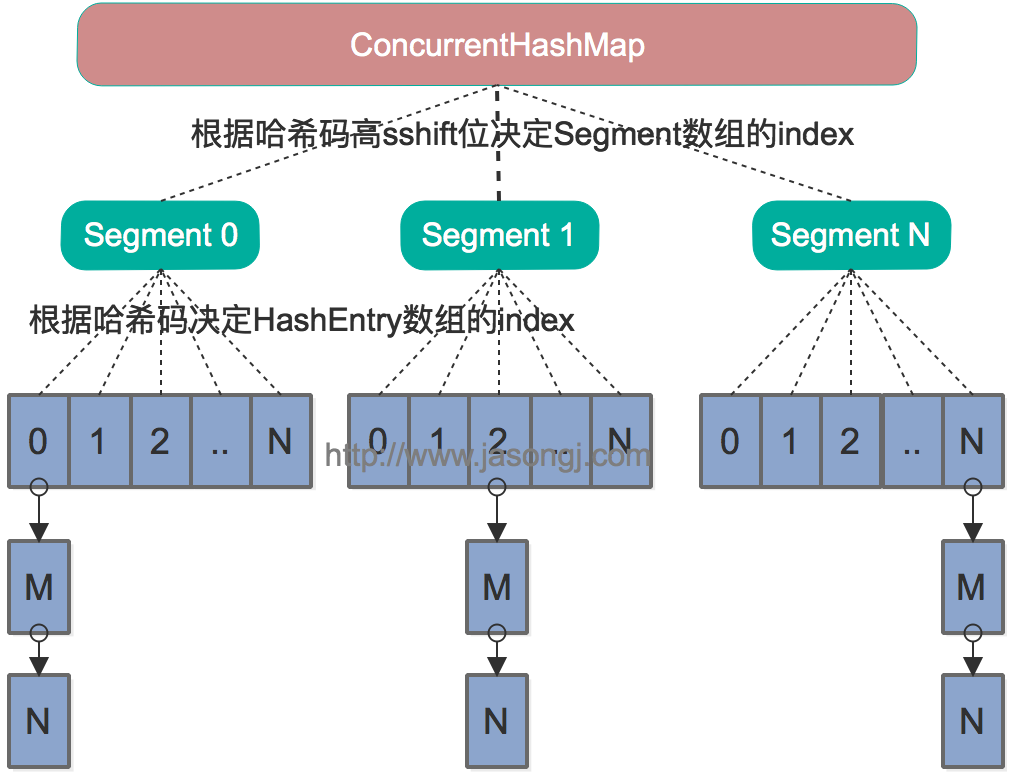
先看图回顾一个java7的ConcurrentHashMap实现。ConcurrentHashMap下面是final segment[],而每个segment都像一个hashMap一样,由volatile HashEntry[]组成。在get时,由于HashEntry[]是volatile,所以不用加锁。当put/remove时,每个segment都继承了ReentrantLock,修改segment的HashEntry[]时要先获取相应的segment的锁,来确保数据安全。其核心想法就是分段锁技术。操作的地方不同,数据不会相互影响,就用不同的锁。
Java8的ConcurrentHashMap
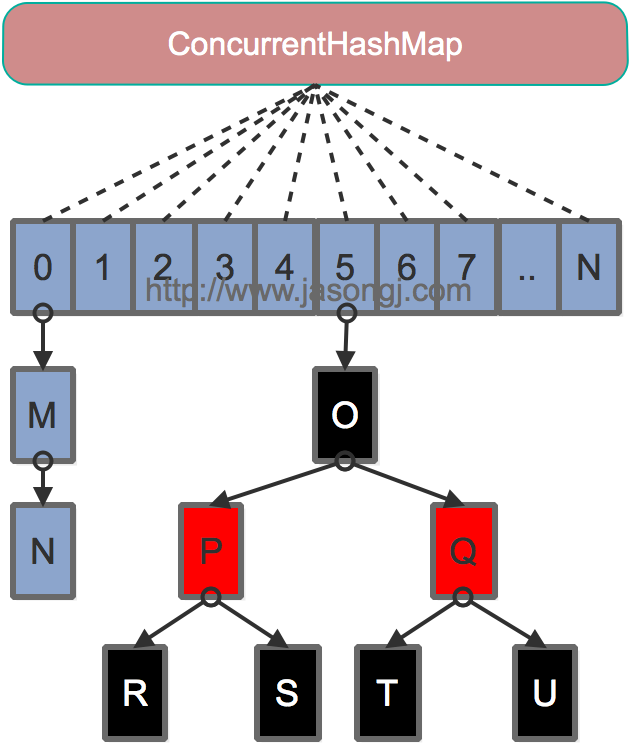
那既然操作的地方不同,数据不会相互影响,就用不同锁。不同的操作地方越多,锁就可以设置越多,并发能力就越高。为何还要segment呢,为何不把这个所谓操作的不同地方的颗粒度尽可能减小,令锁尽可能多呢?因此,java8抛弃的segment这种臃肿的,没有把锁颗粒度最小化的实现方法。取而代之的是,结构恢复hashMap那样,以桶为单位,使用CAS和synchronized进行同步操作。如下图(对,结构压根就跟HashMap一样),结构只有一个Node[]
1 | |
成员变量
1 | |
put操作
- 桶还没初始化,用cas进行初始化
- 桶已经初始化,(且当前该节点不处于移动状态?是啥意思?),就用synchronized加锁。并且该节点的hsah不小于0(?),则:
- 是链表遍历链表插入,否则在红黑树里插入
- binCount不为0的话,证明数据发生了改变(?)。当链表太长,就转变为红黑树。如果oldVal不为空,说明是一次更新操作,没有对元素个数产生影响,则直接返回旧值
- 如果是新插入数据,执行addCount()尝试更新元素个数baseCount
1 | |
get操作
- table为空或者table长度为0或者桶为空,返回null
- 否则判断是链表还是红黑树,尝试查找
1 | |
size操作
不同于1.7在size的时候才计算有多少个。1.8有个volatile的变量baseCount用来记录元素个数。在增添或者删除元素时,会调用addCount()来更新baseCount。至于代码有点复杂,看不懂。
参考文献:
ConcurrentHashMap原理分析(1.7与1.8)
谈谈 ConcurrentHashMap 1.7 和 1.8 的不同实现