word2vec学习小记
词向量
在机器学习中,为了让计算机能够处理自然语言,我们需要用数字来表示自然语言中的词。如果使用一个向量来表示一个词,那这个向量就叫做词向量。把一个词转换为一个向量的方式有很多,例如one hot Representation,以及word2vec。one hot Representation比较简单,通过一个长度为词表大小的(高维)二进制向量来表示,但只能给词编个号,无法表示词之间的关系。另外一种叫做Distributed Representation,使用稠密、低维的实数向量,以“具有相似上下文的词,应该具有相似的语义”的假说提起词义特征,能描述词之间的关系。而word2vec属于Distributed Representation类型。
1 | |
CBOW与Skip-Gram
CBOW与Skip-Gram是两种识词模式。CBOW是通过上下文来推测中间的词,而Skip-Gram则是通过中间的词推测这个词的上下文。
我是上文 我是中间的词 我是下文
CBOW:中间的词→上下文Skip-Gram:上下文→中间的词
词向量的训练
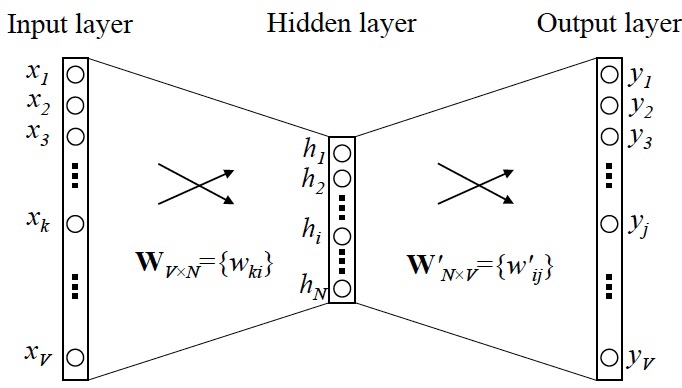
如上图,词向量是通过神经网络来训练的。对于CBOW,把中间词xk的one
hot Representation作为输入,上下文yj的one hot
Representation作为输出,而Skip-Gram则相反。当神经网络训练完成之后,神经网络里的权重就作为词向量。其中,输入层到隐层的权重叫做输入向量,隐层到输出层的权重叫输出向量,一般使用输入向量。
当模型训练完后,最后得到的其实是神经网络的权重,比如现在输入一个 x 的 one-hot encoder: [1,0,0,…,0],对应刚说的那个词语『吴彦祖』,则在输入层到隐含层的权重里,只有对应 1 这个位置的权重被激活,这些权重的个数,跟隐含层节点数是一致的,从而这些权重组成一个向量 vx 来表示x,而因为每个词语的 one-hot encoder 里面 1 的位置是不同的,所以,这个向量 vx 就可以用来唯一表示 x。
此外,我们刚说了,输出 y 也是用 V 个节点表示的,对应V个词语,所以其实,我们把输出节点置成 [1,0,0,…,0],它也能表示『吴彦祖』这个单词,但是激活的是隐含层到输出层的权重,这些权重的个数,跟隐含层一样,也可以组成一个向量 vy,跟上面提到的 vx 维度一样,并且可以看做是词语『吴彦祖』的另一种词向量。而这两种词向量 vx 和 vy,正是 Mikolov 在论文里所提到的,『输入向量』和『输出向量』,一般我们用『输入向量』。
上面是参考文章的片段,如他所说输入输出是one-hot encoder。但显然如果有几百万个词的话,输入输出的维度就会超级高。所以我看别的文章说,通过在输入使用word2vec来降低输入的维度,而最开始的word2vec是随机的。并且对于从输入层到隐藏层的映射,没有采取神经网络的线性变换加激活函数的方法,而是简单的对所有输入词向量求和取平均。
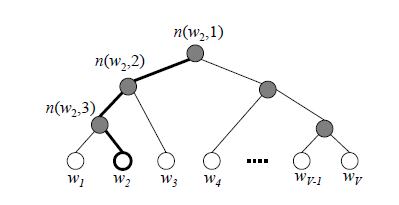
而在输出层的优化上,会使用哈夫曼树,来避免判断全部词。哈夫曼树的叶子节点对应输出层,也就是词有多少个,叶子结点就有多少个。显然,我们需要从根节点一层一层往下走,走到正确的叶子节点那。而往左孩子还是又孩子走决定是通过一个逻辑回归的模型决定的。这个逻辑回归的模型的公式就不贴了,公式中包含当前内部节点的词向量(看不懂啥东西)以及一个每个节点都不一样的,用于调整的参数。最终使得时间复杂度减低为log。
参考文章:
word2vec原理(一) CBOW与Skip-Gram模型基础