Stable Diffusion - 原理篇
本文搜刮整理自网上有关Stable Diffusion的文章,根据个人理解与猜测而写成,如有错漏欢迎指正。
从文本到图片的映射
与ChatGPT类似,一种生成图片的思路是,训练一个模型来预测pixel的分布。每次预测出的新pixel,又会作为预测下一个pixel的输入,直至图片的全部pixel预测完成。
但逐个逐个pixel来预测的速度是太慢了,一张512*512的图片,就要预测26万多次,如果可以每个pixel单独预测,一次输出全部的pixel,速度会有很大的提升。
但将文本映射到图片,图片的信息量是远比文本要多的。要画一只在奔跑的狗,实际可以画出一只在向前/后/左/右奔跑的狗
,也可能是一只在奔跑的黑/白/黄/棕狗。如果每个pixel独立生成,可能每个pixel并不是在画同一个画面,因此生成出来的图像会很糟糕。
因此在常见的图像生成模型里,生成图片的输入并不只文本,还会在正态分布里sample出一个向量,跟文本一起生成图片。这个分布里的每一个向量,就是对应着一只在向前/后/左/右奔跑的黑/白/黄/棕狗。
*图像生成的常见模型
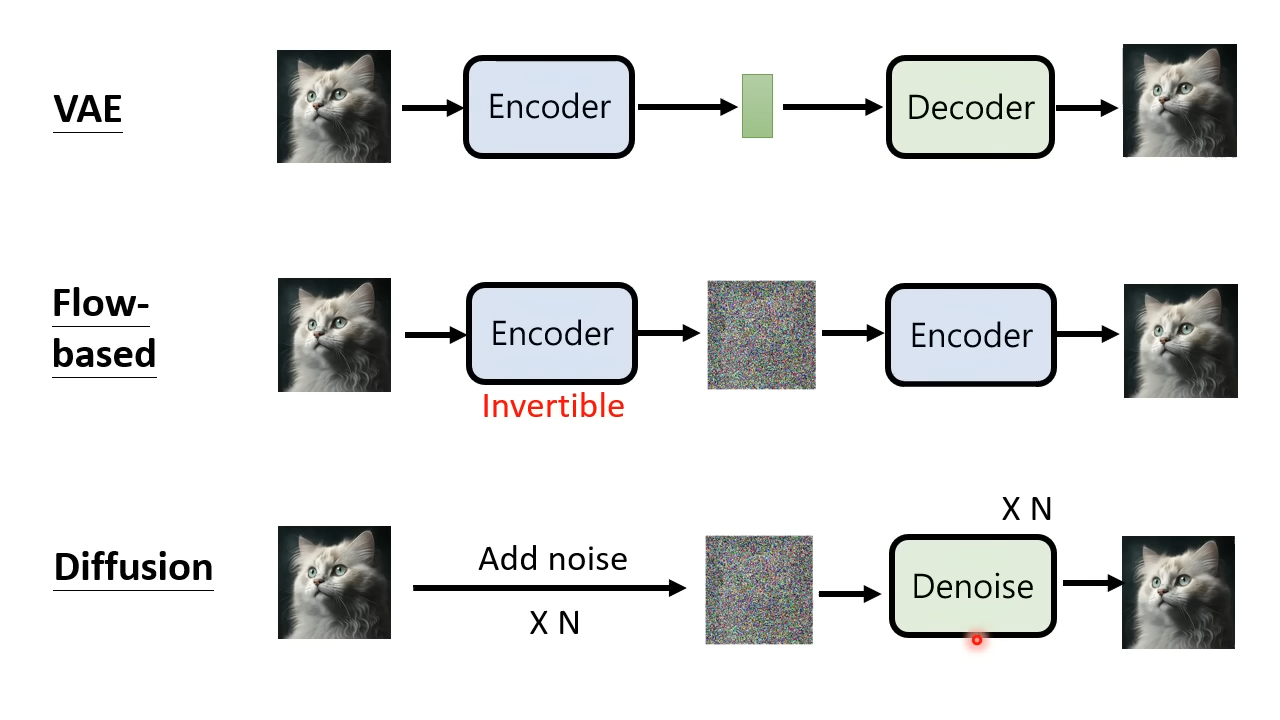
Variational auto-encoder(VAE),变分自编码器
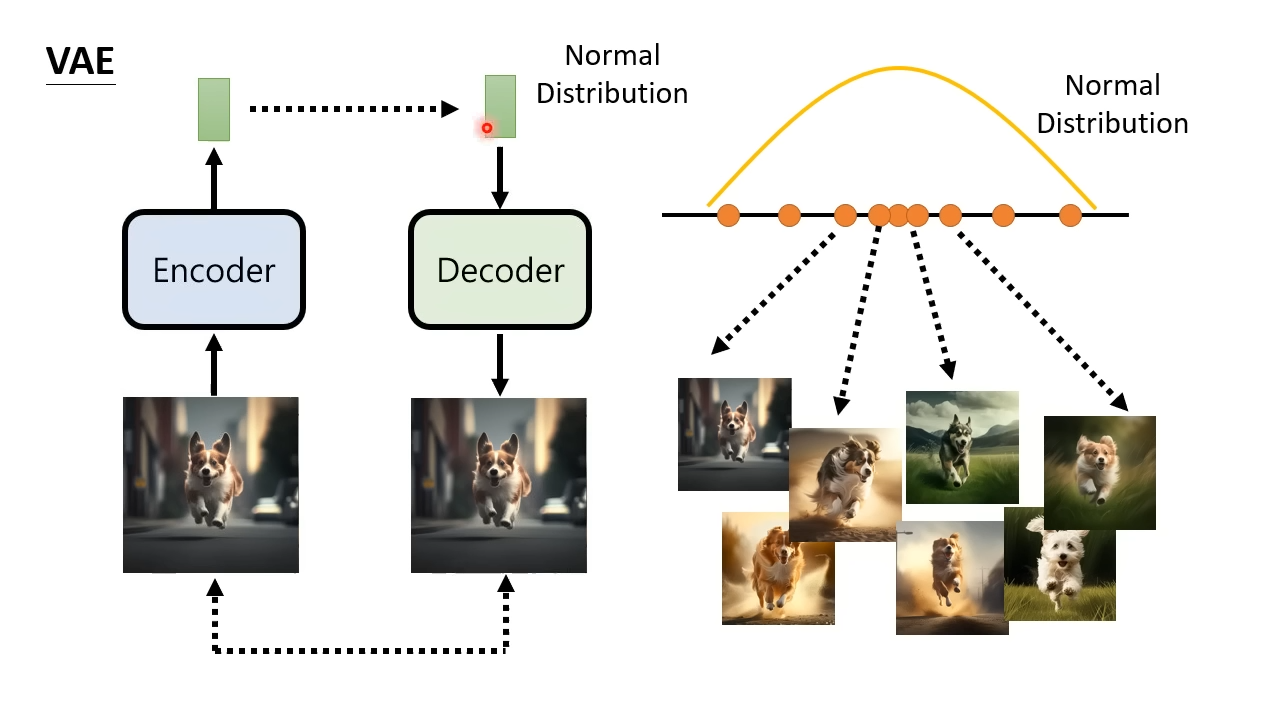
VAE有一个编码器和解码器,会将编码器和解码器连在一起进行训练。编码器输入一张图片,输出一个向量。其中会加一些限制使得这个向量符合正态分布。然后将这个向量作为解码器的输入,输出一张图片,以求得输入输出的图片尽可能相近。训练完成之后就只需要解码器,给解码器输入一个向量,输出一张图片。
Flow-based Generative Model,基于流的生成模型
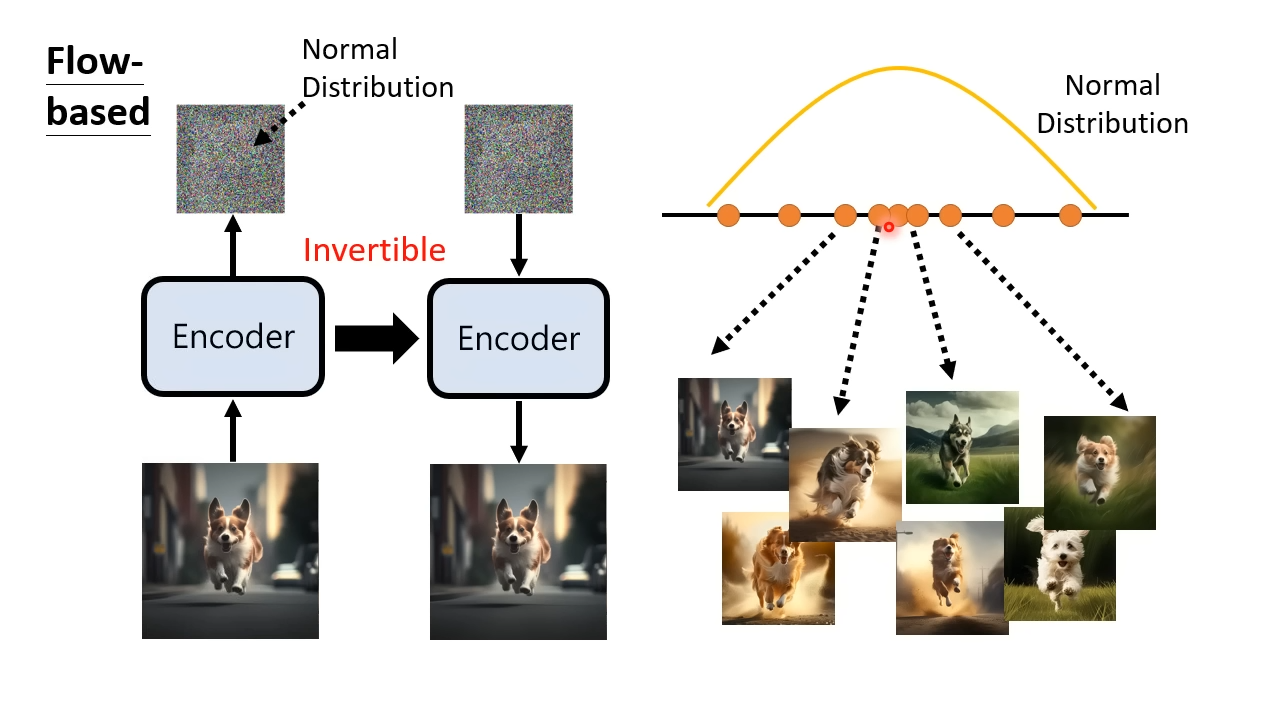
Flow-based训练只有编码器,编码器输入一张图片输出一个向量,同样使得向量符合正态分布。Flow-based对编码器做了限制,使得编码器的可逆的。编码器可逆有两个结果,一个是编码器输出的向量得跟输入的图片同样大小。第二个结果是,训练完成之后就能立即可以将编码器转成解码器,通过解码器产生图片。
Generative Adversarial Networks(GAN),生成对抗网络
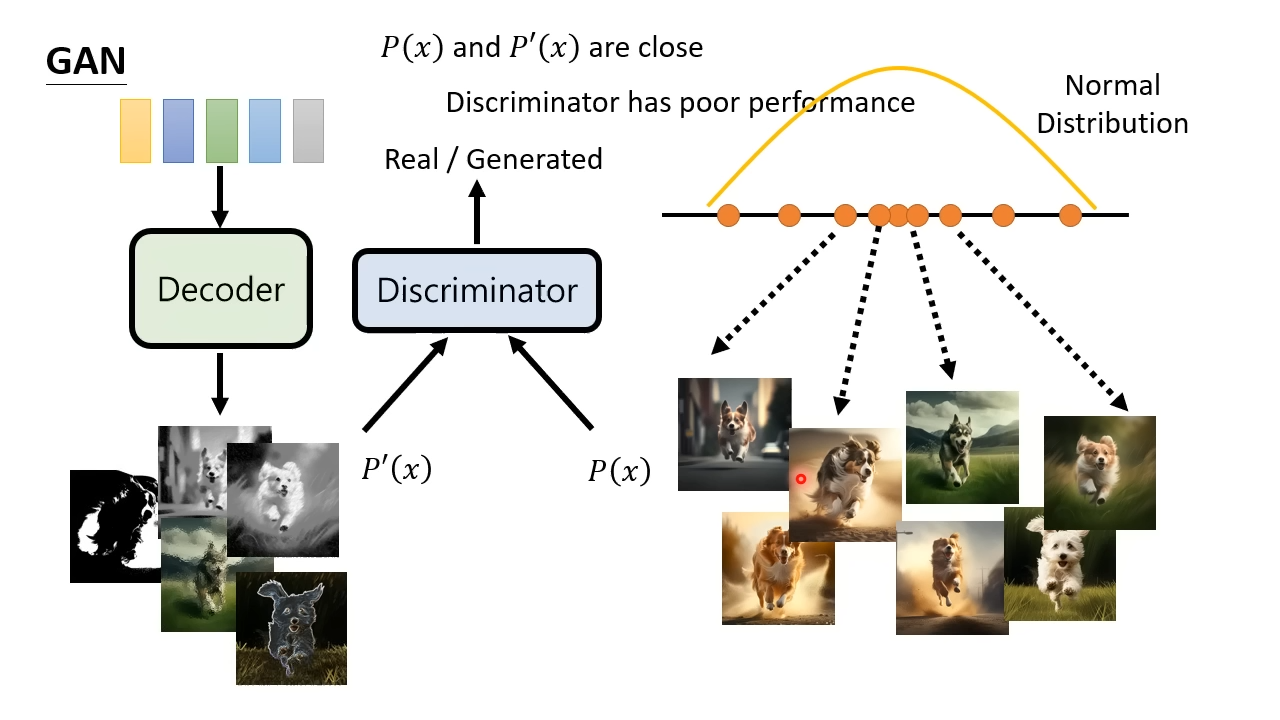
GAN训练有一个解码器和识别器。一开始给解码器输入向量,输出的图片提供给识别器,识别图片是解码器生成的还是真实的图片。识别器提高了识别度之后,会去提升解码器生成图片的真实度。更加真实的解码器图片混合着真实图片又会提升识别器的识别度。训练完成之后就得到了能生成高真实度的解码器。
Diffusion Model,扩散模型
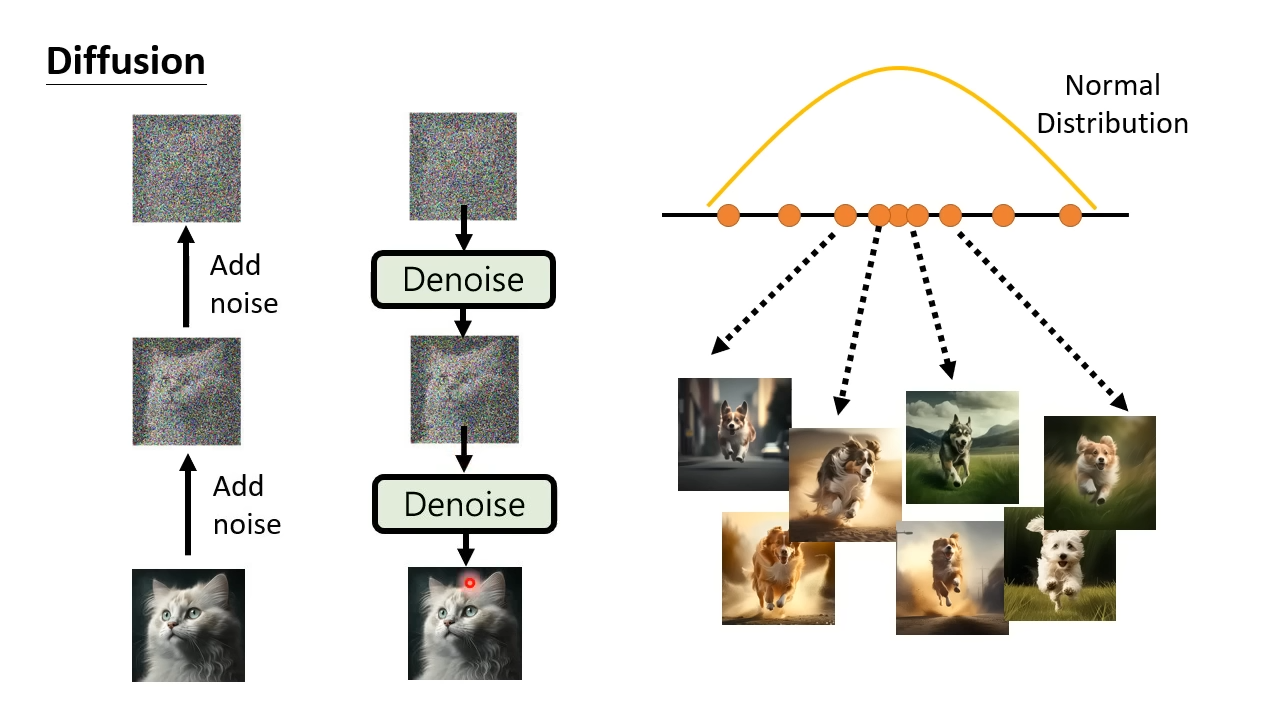
扩散模型核心是降噪器。在训练过程中,会给图片增加一点噪声,最终使得图片变得像在正态分布里随即sample出来的向量一样。在每一次加噪过程中训练降噪器识别噪声。使用训练完成的降噪器,对向量进行多次降噪,得到一张像真的一样图片。
简单对比
 |
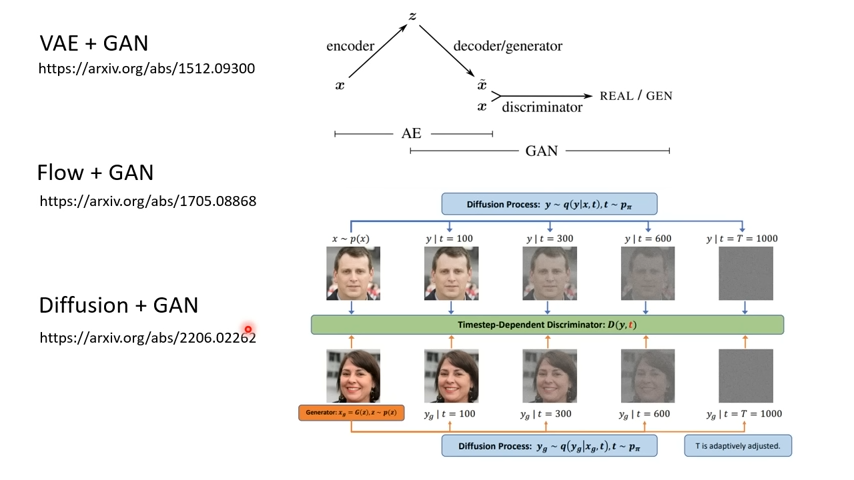 |
VAE、Flow-bases、Diffusion三者都有类型的处理过程,而GAN与这三者并不矛盾,都可以在其解码器后面再接一套GAN来继续训练。
扩散模型
正向扩散与反向扩散,分别对应扩散模型的训练过程与生成图片的过程。
正向扩散
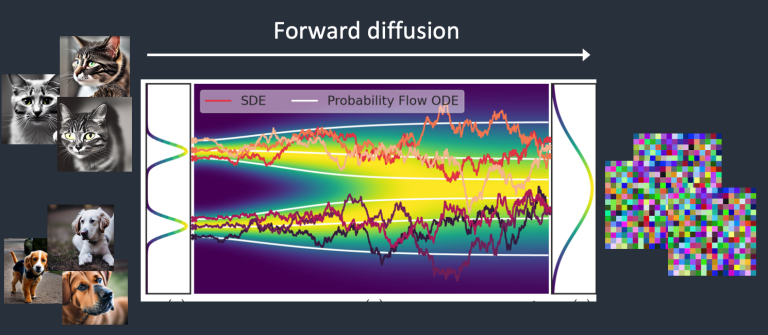
例如我们训练一个只有猫和狗图片的模型。训练集的分布显然不是随机的,能够划分出猫和狗两个集合。而在训练过程中给图片加噪,最终会无法辨识原图是猫还是狗,猫和狗的图片都随机扩散到一个正态分布里,这个过程就是正向扩散。
模型训练
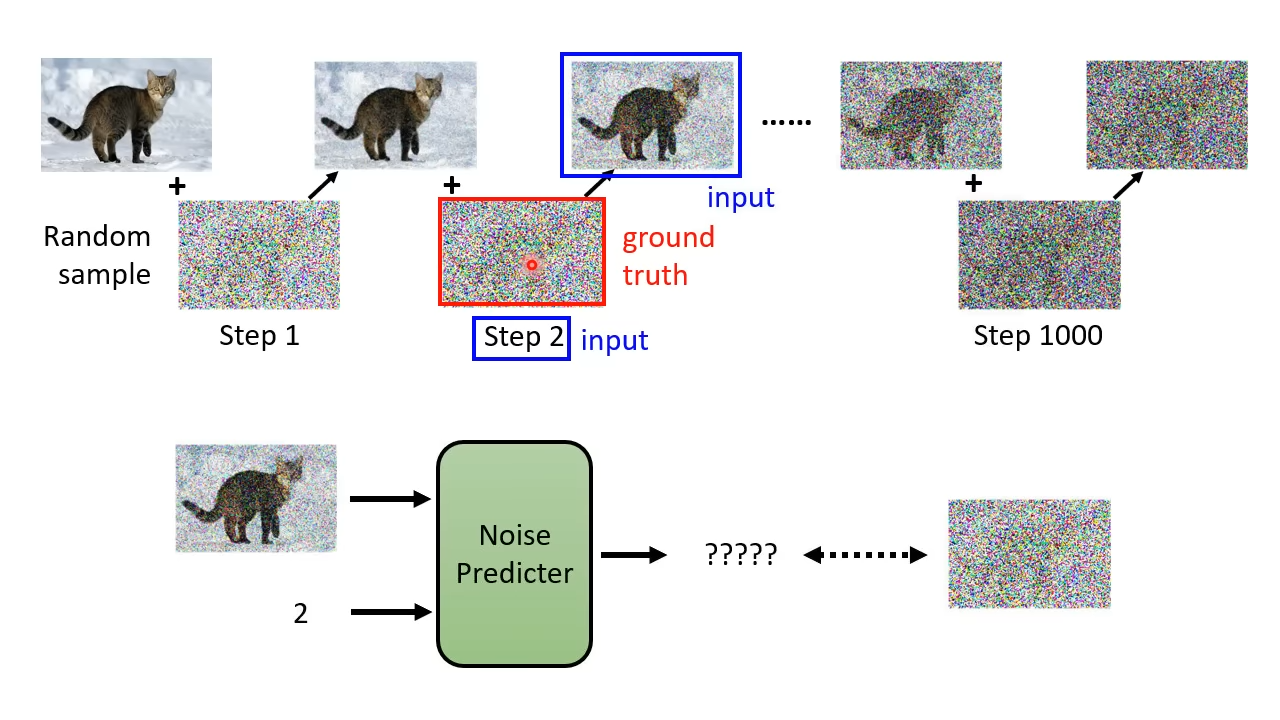
- 从训练集里sample一张图片
- 生成一个随机的噪声
- 将噪声加到图片里生成新的增噪图片,并且记录该图片的噪声编号
- 重复第三个步骤知道预定的噪声次数,并且得到一组噪声,高噪图片和噪声编号
- 将高噪图片和噪声编号丢给噪声预测器训练,以期望噪声预测器输出的噪声与实际噪声越接近越好
反向扩散
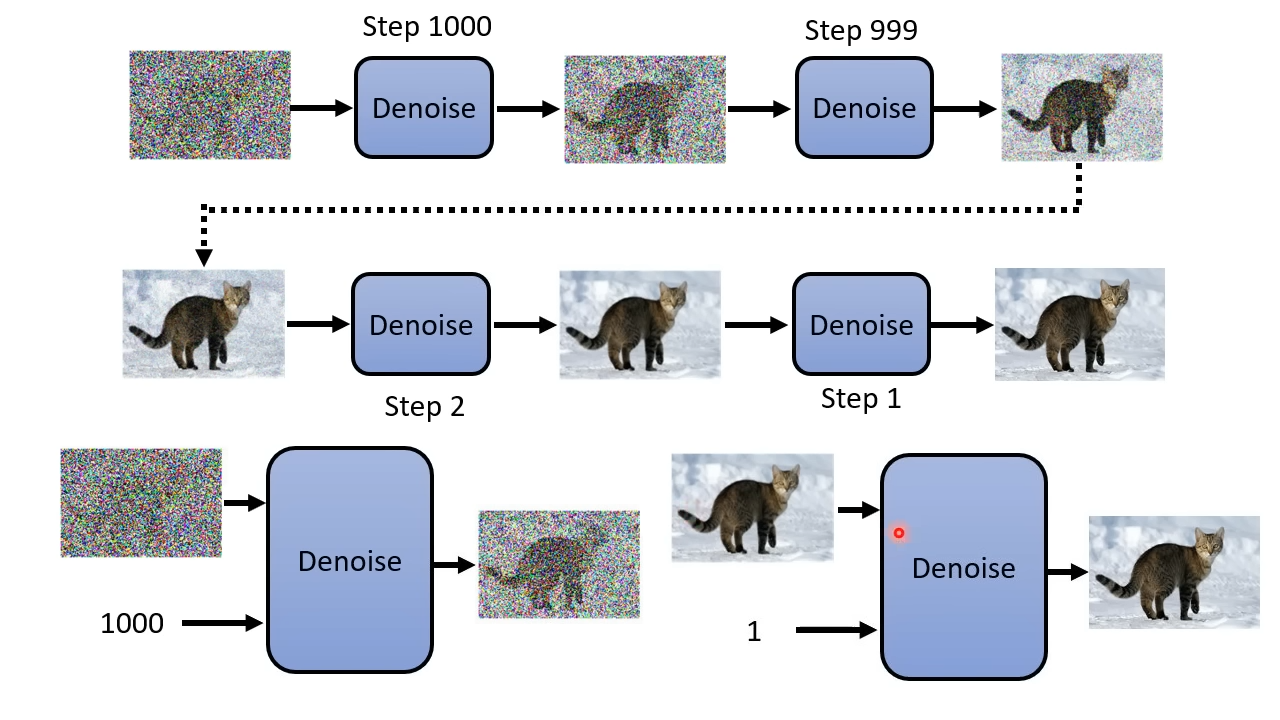
而反向扩散,则为利用降噪器,对来自于正态分布里的随机向量进行降噪,使得向量逐渐收敛到猫集合或者狗集合里。
一般使用降噪器降噪的次数是事先定好的,并且会给每个降噪编一个噪声编号。编号越小越接近最终的图。在每一次降噪中,使用的都是同一个降噪器,但每一次输入降噪器的图片的噪声程度并不一样。为了提高降噪器的降噪效果,会连同把噪声编号也一同输入降噪器,好让降噪器知道图片还有多少噪声,要做多大程度的降噪。
Q:为什么不一步到位,去掉全部的噪声,直接生成最终的图片
降噪器
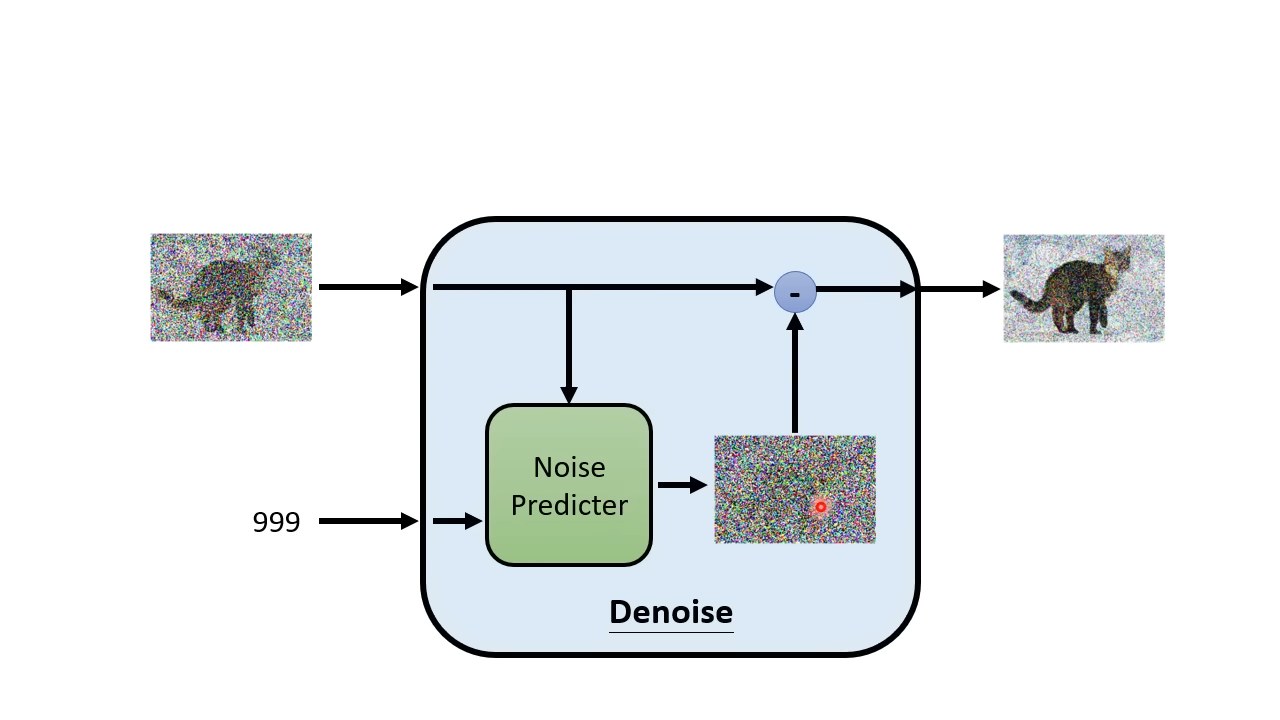
- 降噪器的输入有两个,一个是含有噪声的图片,另一个是噪声编号
- 降噪器内部有一个噪声预测器,输入图片与噪声编号,输出图片里含有那些噪声
- 将图片减去噪声预测器预测的噪声,得到一张噪声更少的图片
Q:为什么不一步到位,直接生成已经降噪的图片,而是要单独先预测噪声,再减去噪声
稳定扩散模型
演算法

我们来看看稳定扩散模型的演算法,稳定扩散模型在实际操作中,跟扩散模型是有些出入的。
- 在训练过程中的噪声,并不是分多次加每次加一点,而是只加一次。经过公式推导,在数学上是跟多次加等效的。
- 在生图过程中则依然会分多次,每次进行部分降噪。但是降噪之后又会加上一点点新的噪声。目的可能是为了避免模型"僵化"
。如果不加上新的噪声,实际上并无法生成正常图片。
潜空间
对于一张512*512*RGB的图片来说,占用空间还是很大,速度也很缓慢。所以稳定扩散模型使用VAE,将图片进行压缩转换到潜空间。因此稳定扩散模型并不是对图片直接加噪,而是对潜空间的图片加噪,完成正向扩散。同样的,反向扩散也是对潜空间的图片进行去噪,最后才使用VAE对去噪完成的潜空间图片,转换成最终图片。
使用VAE将图片压缩进潜空间,再从潜空间将图片解压,只能保留图片的主要信息,一些细节会丢失,是一个有损过程。尽管如此,VAE有一定能力去脑补重绘丢失的细节。因此使用不同的VAE模型,可以对最终生成的图片进行微调,绘制更加精细的细节,优化改善眼睛和脸部等。
模型结构
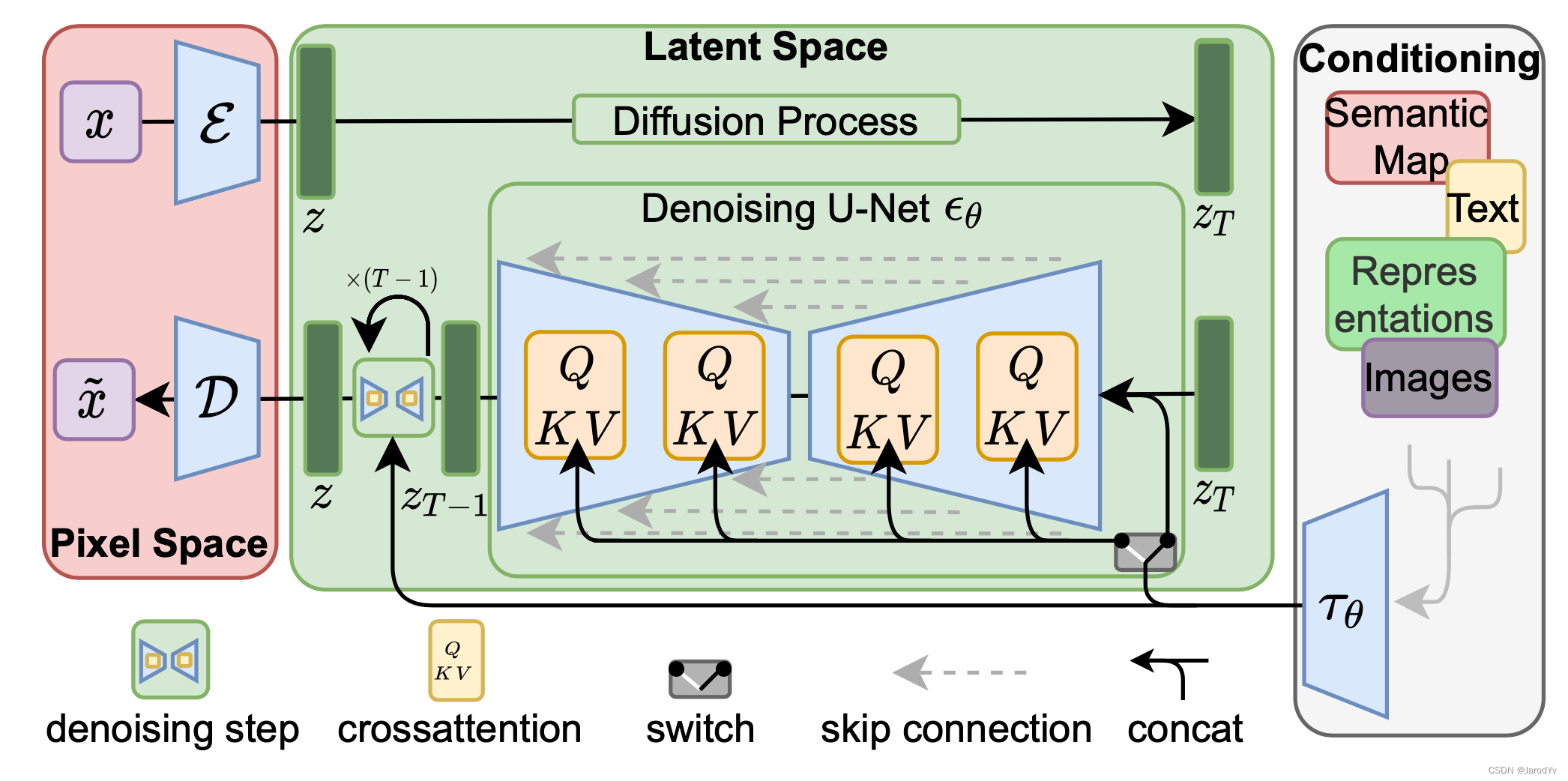
- x:输入图像;x~:生成图像
- ε:潜空间编码器;D:潜空间解码器
- z:潜向量;zT:噪声潜向量
- τθ:文本/图像的控制编码器
- 输入图像x经过潜空间编码器ε,被压缩成了潜向量z,进入潜空间
- 潜向量z经过加噪,变成噪声潜向量zT
- 控制数据经过控制编码器τθ,转变成控制向量
- 噪声潜向量zT,连同控制向量一起,被输入降噪器。经过一次降噪,生成了噪声潜向量zT-1
- 上一步骤经过T次,变回潜向量z
- 潜向量z经过潜空间解码器D,解压缩为生成图像x~
其中将控制数据经过编码器τθ,转变成控制向量的步骤。就是实现以文生图、以图生图的关键,理论上只要能编码成向量,丢进噪声预测器里一起算,就能一定程度控制图片的生成。
模型微调
尽管网上SD的大模型林林总总各式各样,但是为了适配的不同口味,有着大量的对大模型进行调整的需求。训练一个新的大模型所要求的算力与数据量并非普通人所能负担,但盲目调整大模型的权重,容易导致大模型遗忘先验知识。因此衍生出了各种各样的微调方法,主要的思路都是锁定大模型的权重,通过添加更多的网络层来对模型进行调整。
Textual Inversion,文本反转
在以文生图的过程中,提示词会经过控制编码器转成向量,向量输入到模型中寻找在训练过程中学习到的对应画法。但如果遇到了一种不知道怎么用现有概念来描述,只能起个新名称来定义的新概念,新名称在模型训练时没学习过,这时候就会懵逼了。文本反转寻找一个能让大模型理解新名称新概念的一种方法。
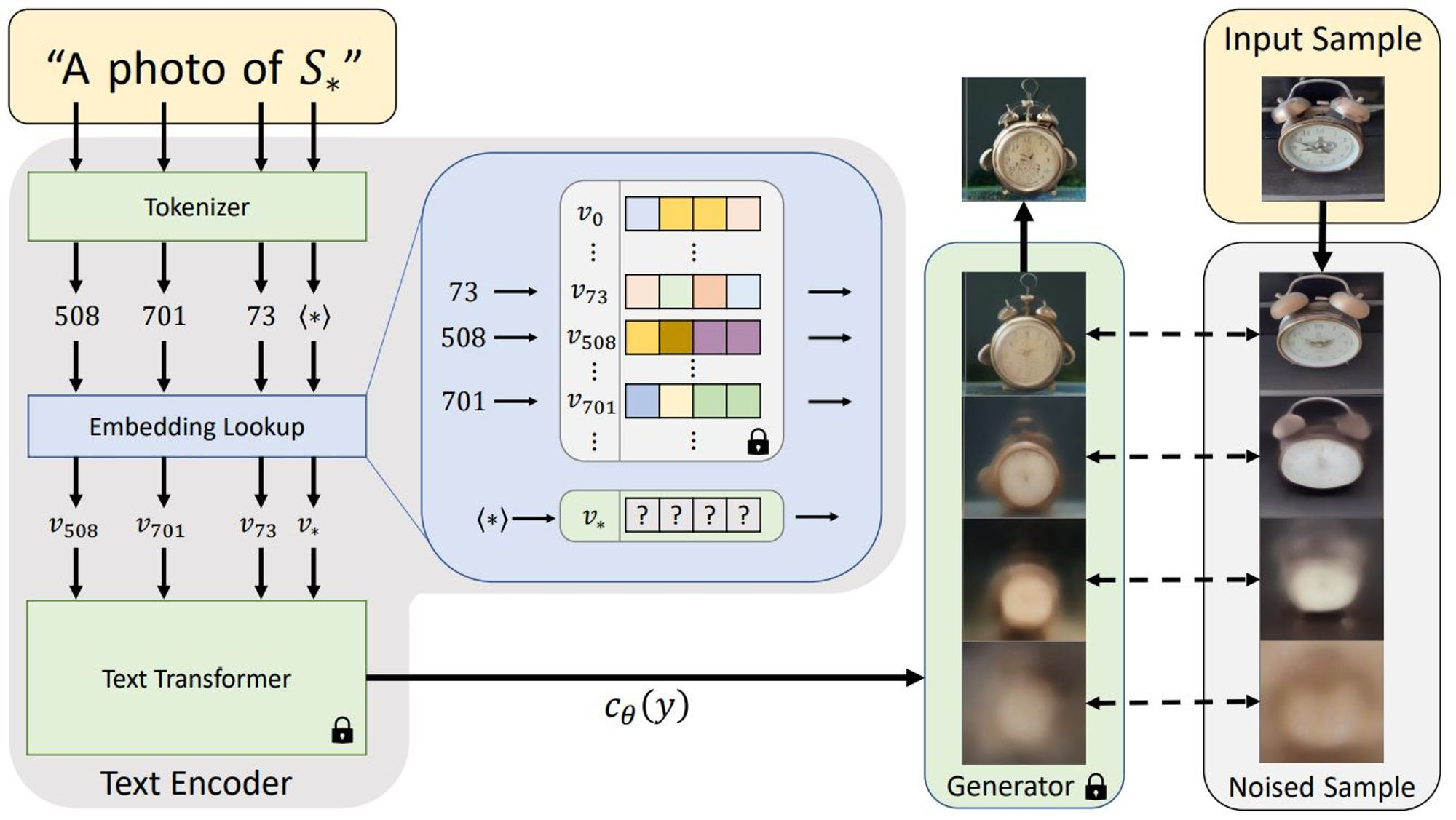
- 既然是新概念,首先会给这个新概念起一个新名称S*。
- 使用控制编码器把S*转变成向量ν*。一开始控制编码器是懵逼的,因为没见过这个新词,只能装模作样随便编个向量出来。
- 大模型面对这个随便编的向量,虽然会觉得莫名其妙,画出来的东西也莫名其妙,但由于大模型的权重是被锁定的,也只能照画了。
文本反转的训练过程则是期望画出来的话,跟给到的训练集越像越好。在训练过程中就会学习到训练集图片里共有的部分,丢弃掉不同的部分。由于只有控制编码器的权重能够训练,所以会迫使控制编码器寻找大模型能理解能画对的向量,来描述新名称
S*。最终训练出来的控制编码器就是产物模型了。
特点
- 在高精度生成的方面可能会有不足。因为只是训练控制编码器,通过大模型现有能理解的,尽量给大模型描述新概念的模样,并非大模型真的学到了这个新概念,所以本质上会有些缺失
- 学习一个新概念大概需要1-2小时
- 在不同大模型上效果不一致。除非是基于同一个大模型训练的,所以很难重现效果
- SDv1训练出的模型跟SDv2不能通用,因为SDv1跟SDv2的控制编码器模型并不是一个模型
Hypernetwork,超网络
超网络是一个非常小的神经网络,会像插件一样,附加到大模型的噪声预测器的注意力交叉模块里,当然在训练过程中,大模型的权重是锁定的。
超网络的原理没找到什么比较通俗易懂的解释。按我理解的话,文本反转是在大模型外部,提高给大模型的解说能力。而超网络则是在大模型内部,扩大大模型的理解范围,实现对控制编码器生成的新向量的理解。
特点
- 存储体积大,相比文本反转和LoRA系列
- 作用效果的控制力比较尴尬,作用范围很难去掌控
- 不同模型上效果不一致
DreamBooth
DreamBooth与文本反转有些类型,但有几个不同的点。
- 文本反转是创建一个全新的词,而DreamBooth则是使用一个罕见的词。常见词往往有更加丰富的含义。使用罕见的词是为了避免在训练过程中,把常见词的含义给训练偏了(语义漂移)
- 文本反转训练的是控制编码器,而DreamBooth训练的是控制编码器+大模型。
- 为了避免大模型时遗忘先验知识,DreamBooth在训练过程中鼓励不断生成与我们的主题相同但类别的不同图,不断巩固已经学到的知识。
特点
- 训练过程相比其他方法更消耗显存内存。毕竟训练的是大模型。
- 体积大。毕竟训练的是大模型。
- 调整(也可以认为是破坏)了原有模型,可能会出现一些原模型没有的缺点。
- 控制能力差(不能即插即用)
Low Rank Adaption(LoRA),低秩适配
跟超网络类似,LoRA会在注意力交叉模块里插入新的数据处理层,用以调整大模型。但是注意力交叉模块里的参数量很大,如果直接插入一个层,那参数量就得一样大了。为了解决这个问题,LoRA的权重实际上是以矩阵相乘的形式存储(低秩适配的本意其实是指这)。训练则是跟DreamBooth类似,也是训练控制编码器+大模型。
- 效果弱于DreamBooth,主流的训练方式的网络结构目前在尽量追求DreamBooth的效果,但是具体效果是很多因素影响的。
- 成分复杂(你不知道你的LoRA究竟是用哪种网络结构训练出来的,LoRA的方式训练确实太好用了),用前建议鉴别来源。
- 控制力弱(虽然即插即拔,但是LoRA训练方法混乱,训练成品良莠不齐,很难有效把控)
- 不同模型效果不同
ControlNet
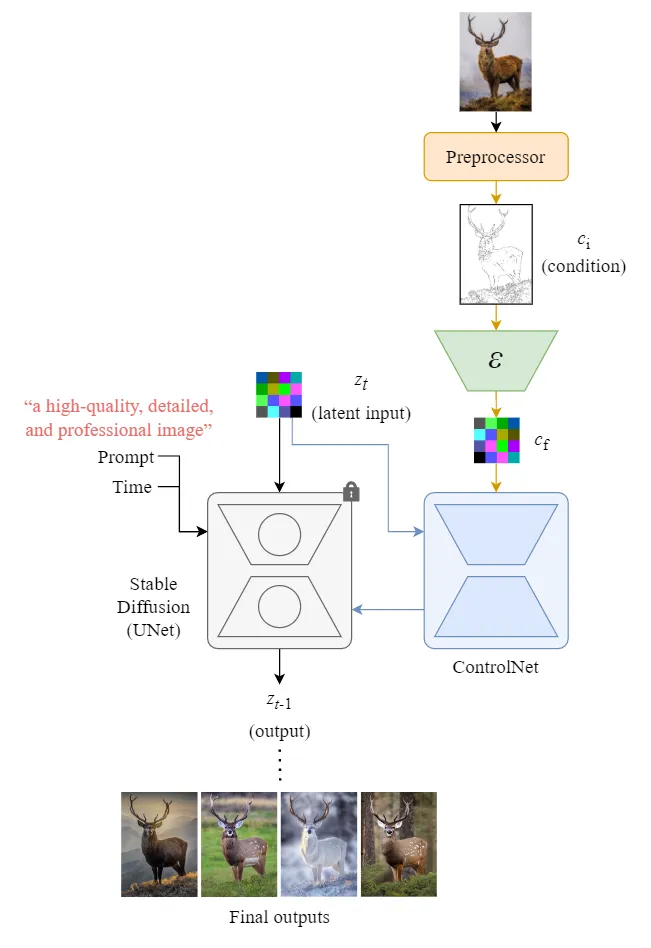
ControlNet则是对UNet做手脚。ControlNet训练也会锁定UNet的权重,然后创建一份UNet的副本用作训练。使用副本而不是直接在原本的UNet里训练,好处是能降低小数据集训练过拟合,并且保留原模型的能力。
- 图片经过预处理器,生成控制条件ci
- ci经过编码器ε,压缩成控制向量cf,进潜空间
- ControlNet会把噪声潜向量zt与控制向量cf都作为输入
- ControlNet的输出会与UNet的输出"加一起",作为整个结构的输出zt-1
本文最后
本文最后,总得写些大逆不道的个人感想。
- SD并不知道自己在画什么,也不知道为什么要这么画,它只是努力地把画画的像画而已
- SD在22年8月发布,同年9月就大火了,到现在23年都已经有些退烧了。但为什么我现在才来关注SD呢。是因为我在微信营销号里突然刷到说SD能生成艺术化二维码,我就眼睛一亮里。我以为是给SD直接丢一个链接和一张底图,就能生成出来。
- 但实际上是得先生成二维码图片,SD再对二维码图片进行艺术化。过度的艺术化依然会破坏二维码,而要进行多大程度的艺术化,还是得靠人来抽卡。
- 这有什么重要的吗?如果是链接加底图就能生成二维码,这意味着SD能理解链接与二维码之间的关系,这样二维码才能被扫出来。并且也可能能一定程度上理解它自己在普通画画时候画的是什么,为什么要这么画。这样才能做到在不破坏二维码的前提下融入艺术化。
- 结果是,SD能很努力地画一张很像二维码的二维码,但这与画一张能扫的二维码的难度就不是一个级别的。
- 期待更多像ControlNet一样,比ControlNet更加受控/精细/通用/强大的插件,成为新时代的PS
- 但话说回来,又不是不能
用画。 - ControlNet给我展示到了像PS一样,可以安装各种各样的笔刷,使用各种各样的工具对图片进行编辑。只不过SD能给到的工具更加强大。
- 但毕竟SD是不知道自己在画什么的,所以不能称得上智能,因此SD就得能够在发挥自己强大画画能力的同时,提供到更加受控,更加精细,更加通用的使用方法给人工控制。这样的话,替代PS指日可待。
- 但话说回来,又不是不能
参考文献
How does Stable Diffusion work? - Stable Diffusion Art
https://www.youtube.com/watch?v=z83Edfvgd9g
Stable Diffusion原理详解_人工智能_jarodyv_InfoQ写作社区
十分钟读懂Stable Diffusion运行原理 - 古道轻风 - 博客园
Jay Alammar 再发新作:超高质量图解 Stable Diffusion,看完彻底搞懂「图像生成」原理 - IT之家
The Illustrated Stable Diffusion
StableDiffusion-ControlNet工作原理[译] - AI备忘录