临急抱佛脚之杂七杂八
java程序设计语言
String类为什么是final的
final char[],但数组的值可变,为了不被重写方法修改char[]值,所以final String维持不可变性。
String、Stringbuilder、Stringbuffer 区别
Stringbuilder不是线程安全,Stringbuffer是线程安全。当有大量字符串操作时,效率:Stringbuilder》Stringbuffer》String
Class.forName和classloader的区别
一个类的装载有三个过程:加载(将class文件读取到jvm里),连接,初始化(执行类的静态块)。而Class.forName会执行初始化过程,classloader不会。
1 | |
测试代码
1
2
3
4
5
6
7
8
9
10package reflect;
/**
* Created by cellargalaxy on 17-10-21.
*/
public class People implements HelloSay{
static {
System.out.println("执行了People的静态块");
}
//。。。
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/**
* Class.forName与classLoader的区别
*/
private static void test13() throws ClassNotFoundException {
ClassLoader classLoader=ClassLoader.getSystemClassLoader();
Class clazz=classLoader.loadClass("reflect.People");
System.out.println("classLoader加载"+clazz);
}
/**
* Class.forName与classLoader的区别
*/
private static void test12() throws ClassNotFoundException {
Class clazz=Class.forName("reflect.People");
System.out.println("Class.forName加载"+clazz);
}
运行结果
1
2
3
4
5//test12()
执行了People的静态块
Class.forName加载class reflect.People
//test13()
classLoader加载class reflect.People
所以在JDBC中,使用的是Class.forName("com.mysql.jdbc.Driver")
1
2
3
4
5
6
7static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
session和cookie的区别和联系,session的生命周期
| 对象 | 保存时间 | 应用范围 | 保存位置 |
|---|---|---|---|
| Session | 用户活动时间+一段延迟时间(默认20分钟) | 单个用户 | 服务器端 |
| Cookie | 浏览器周期 | 单个用户 | 客户端 |
浏览器访问服务器时,服务器会按需要创建一个session对象。这个session对象有一个唯一的id,这个id默认通过cookie机制发送给浏览器,当浏览器再次访问服务器时会带上这个cookie,服务器就会根据这个cookie查找对于的session。所以session是基于cookie的。如果浏览器禁用了cookie,可以通过url重写或者隐藏的表单域的方法向服务器提交cookie。url重写既是把cookie写在url的参数上,隐藏的表单域法就是创建一个隐藏的表单域,在浏览器提交表单时把表单的cookie信息随便提交给服务器。
数据结构
几个Java集合类
List集合类:ArrayList,LinkedList
Set集合类:HashSet,TreeSet
Map集合类:HashMap,TreeMap
ArrayList和LinkedList各自实现和区别
ArrayList是对数组操作的分装,数组大小不够时需要进行扩容。在前面或者中间进行增删操作需要移动后面的元素,时间复杂度O(n)。查找通过下标查找,时间复杂度O(1)。LinkedList是由节点构成并存储数据,不需要进行扩容,任意的增删操作时间复杂度O(1)。查找需要按顺序一个一个节点查找,时间复杂度O(n)。需要大量随机查找ArrayList好,需要大量前面或者中间插入LinkedList好。
Java中的队列都有哪些,有什么区别
相比于普通队列,阻塞队列会在队列为空而从队列里获取数据,会被阻塞,直到有数据被添加到队列里。同样,当队列已满,往队列里添加数据会被阻塞,知道有数据被移除为止。
- ArrayDeque 双向队列
- LinkedBlockingDeque 阻塞双端队列
- ArrayBlockingQueue 双向并发阻塞队列
- LinkedBlockingQueue FIFO 队列
- ConcurrentLinkedQueue 基于链接节点的无界线程安全队列
- PriorityBlockingQueue 带优先级的无界阻塞队列
Java虚拟机
Java内存泄露的问题调查定位
jmap用于获取jvm某个时刻的快照,导出为dump文件。
jstat可以用来某个Java进程内的线程堆栈信息。
1
2
3jstat -gc pid
#可以显示gc的信息,查看gc的次数,及时间
#其中最后五项,分别是young gc的次数,young gc的时间,full gc的次数,full gc的时间,gc的总时间
jvm参数,堆内存大小
- -Xms:启动JVM时的堆内存空间
- -Xmx:堆内存最大限制
Java并发编程
直接调用并发编程start()方法和run()的区别
直接调用run方法只是普通的调用,也要等到run方法返回了才能继续往下执行。而调用start方法将启动一个线程,线程从创建状态转变成就绪状态。当线程获得cpu时间,start方法将会调用run方法。
常用的线程池模式以及不同线程池的使用场景
- newCachedThreadPool:创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程
- newFixedThreadPool:创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待
- newScheduledThreadPool:创建一个定长线程池,支持定时及周期性任务执行
- newSingleThreadExecutor:创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序 (FIFO, LIFO, 优先级) 执行
了解可重入锁的含义,以及ReentrantLock和synchronized的区别
重入锁是同一个线程可以多次获取同一个锁。synchronized需要一个对象作为锁对象,代码进入synchronized块即获取锁,报异常或者离开synchronized块jvm或自动是否锁,避免锁死。ReentrantLock通过计数器作为标志加锁,获取锁需要显式声明,所释放需放在finally里,需要手动释放,避免死锁。在低并发下,synchronized好,在高并发下,synchronized效率会下降几十倍,而ReentrantLock效率比较稳定。ReentrantLock除了synchronized的功能,多了三个高级功能:等待可中断,公平锁,绑定多个 Condition。
Spring
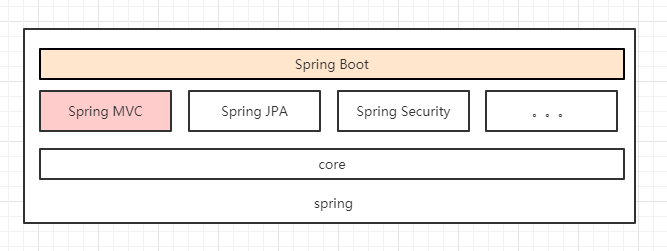
Spring,Spring MVC及Spring Boot区别
Spring一般指的是Spring Framework,核心容器(Spring Code)提供控制反转(IOC)功能。在核心容器的控制反转功能上,继续开发了:
- Spring AOP
- Spring JDBC
- Spring MVC
- Spring ORM
- Spring JMS
- Spring Test
- 等等
可见,Spring MVC是一个基于Spring的MVC框架。随着功能越来越多,配置文件越来越臃肿,虽然后来加入了注解的配置方法,但是还是好麻烦。所以Spring Boot以约定优于配置原则,对Spring各个功能都有一套默认的配置,免除开发时反复粘贴默认习惯的配置,实现自动配置,降低项目搭建的复杂度。使用这些默认配置只需在pom.xml引入Spring Boot的starter形式的依赖。
- spring-boot-starter-web-services:针对SOAP Web Services
- spring-boot-starter-web:针对Web应用与网络接口
- spring-boot-starter-jdbc:针对JDBC
- spring-boot-starter-data-jpa:基于hibernate的持久层框架
- spring-boot-starter-cache:针对缓存支持
- 等等
基于JDK代理和cglib的AOP实现有什么区别
动态代理有两种,一种是JDK自带的东塔代理,另一种是使用asm开源包的cglib动态代理。因此,Spring的切面编程(AOP)也有两种实现。JDK的动态代理需要获取被代理类的接口,代理类实现被代理类的接口并顺便代理。因此JDK动态代理只能代理接口而不能代理类。而cglib能代理类,他是通过继承被代理类来代理的,因此使用cglib的被代理类及其全部方法都不能被声明为final。
监听器,拦截器的作用区别
监听器Listener,实现了javax.servlet.ServletContextListener接口,随web应用的启动而启动,只初始化一次,随web应用的停止而销毁,用来进行一些初始化操作。过滤器Filter,实现了javax.servlet.Filter接口,对指定路径的请求进行拦截,用来做字符编码,用户登录的检查等。
Tomcat跟servlet的关系
Tomcat是一个免费的开放源代码的Servlet容器,Servlet是tomcat的组件。tomcat接收客户请求,创建出HttpRequest对象和HttpResponse对象,将HttpRequest对象和HttpResponse对象传递给Servlet,Servlet根据HttpRequest对象和HttpResponse对象返回响应数据给tomcat,tomcat再把响应数据返回给客户。
Servlet生命周期
Servlet生命周期总共分为三个步骤
- 调用
init()方法初始化,只调用一次 - 调用
service()方法来处理客户端的请求,service方法会检查HTTP请求类型,调用 doGet、doPost、doPut、doDelete 方法 - 调用
destroy()方法释放资源,标记自身为可回收,Servlet 生命周期结束时调用
MySQL
MySQL引擎的特点
| 特性 | MyISAM | InnoDB | Memory | Archive | NDB | BDB | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 存储限制 | No | 64TB | Yes | No | Yes | No | |||||
| 事务 | × | √ | × | × | × | √ | |||||
| MVCC | × | √ | × | √ | √ | × | |||||
| 锁粒度 | Table | Row | Table | Row | Row | Page | |||||
| B树索引 | √ | √ | √ | × | √ | √ | |||||
| 哈希索引 | × | √ | √ | × | √ | × | |||||
| 全文索引 | √ | 5.6支持e文 | × | × | × | × | |||||
| 集群索引 | × | √ | × | × | × | × | |||||
| 数据缓存 | × | √ | √ | × | √ | × | |||||
| 索引缓存 | √ | √ | √ | × | √ | × | |||||
| 数据压缩 | √ | × | × | √ | × | × | |||||
| 批量插入 | 高 | 相对低 | 高 | 非常高 | 高 | 高 | |||||
| 内存消耗 | 低 | 高 | 中 | 低 | 高 | 低 | |||||
| 外键支持 | × | √ | × | × | × | × | |||||
| 复制支持 | √ | √ | √ | √ | √ | √ | |||||
| 查询缓存 | √ | √ | √ | √ | √ | √ | |||||
| 集群支持 | × | × | × | × | √ | × |
MyISAM
MyISAM是mysql默认的引擎。需要经常执行OPTIMIZE TABLE命令来消除碎片,否则会影响效率。
优点:与操作系统独立。大量查询和插入时速度快。单独保存表行数
缺点:不支持事务,行锁和外键。update效率低InnoDB
优点: 支持事务,自增长列,外键。使用颗粒度小的行锁,写和更新操作高。提供系统奔溃修复能力,支持自动灾难恢复。MEMORY
优点:使用内存储存,有很高性能
缺点:mysql守护进程奔溃时,内存里的数据会全部丢失。不可使用长度可变数据类型(如BLOB和TEXT),但varchar类型可用(varchar在MySQL内部被当做char类型)CSV
使用csv文件保存数据。不支持索引,没有主键,不允许为空ARCHIVE
ARCHIVE适合存储大量独立、作为历史记录的数据。ARCHIVE提供压缩功能,插入高效,但不支持索引,查询较慢。
MySQL最左匹配原则
例如建立了一个索引(a,b,c),则相当于建立里(a),(a,b),(a,b,c)三个索引。
### 全列匹配
例如where a=1 and b=2 and c=3,使用了索引(a,b,c)。理论上where语句的顺序会影响,但是mysql会调整顺序以使用适合的索引。
### 最左前缀匹配
where只有索引连续的前几个,例如where a=1 and b=2,使用到索引。
### 查询条件用到了索引中列的精确匹配,但是中间某个条件未提供
例如where a=1 and c=3,因为没有b,所以所以只使用到a索引。在a的结果再对c进行过滤。
### 查询条件没有指定索引第一列
没法用到索引
### 匹配某列的前缀字符串
例如where a=1 and b like 'Senior%',此时可以用到索引,但需要通配符%不出现在开头。
### 范围查询
例如where a < 1 and b=2,范围列可以用到索引,但是范围列后面的列无法用到索引。所以如果查询条件中有两个范围列则无法用全到索引。
### 查询条件中含有函数或表达式
没法用到索引
事务的四个特性
原子性:即一个事务要不全部完成,要不全部失败。如果失败不能对数据库有任何影响。
一致性:完成一个事务,数据库是从一个一致状态转变到另一个一致状态。即事务前后,数据库的数据都需要一致正确。
持久性:一旦一个事务完成,即便是数据库奔溃,操作依然不会丢失。
隔离性:当并发执行多个事务时,各个事务之间不能相互干扰。
事务的隔离级别
脏读:读取到了其他还没提交的事务修改的数据
不可重复读:在同一个事务中多次读取同一个数据,由于期间被其他事务所修改,其数据的值并不一样。与脏读读取到的是未提交的数据不同,不可重复读读取到的是前一个事务提交了的数据。
幻读:不是很理解,看了几篇文章都没有比较精炼的语言来概括,这里就只能举个例子:一个事务读取2次,得到的记录条数不一致,由于2次读取之间另外一个事务对数据进行了增删。
- Serializable (串行化):可避免脏读、不可重复读、幻读的发生
- Repeatable read (可重复读):可避免脏读、不可重复读的发生
- Read committed (读已提交):可避免脏读的发生
- Read uncommitted (读未提交):最低级别,任何情况都无法保证
数据库连接池
使用数据库连接池能重复利用数据库连接。创建销毁一个数据库连接需要花费大量开销。数据库连接池能先建立一些数据库连接,但程序需要使用数据库连接是,直接从数据库中获取,使用完归还给数据库连接池,提高程序的响应速度。数据库连接池的存在使得可以统一管理数据库连接,限制程序所创建的连接数,避免单一程序占用过多的连接资源。还可以设置连接占用时间,避免连接泄露(就是连接被异常情况一直占用)
@Scheduled注解实现定时任务
第一步,需要在Spring
Boot的主类中加入@EnableScheduling注解,启用定时任务的配置
@Scheduled(fixedRate = 5000):上一次开始执行时间点之后5秒再执行
@Scheduled(fixedDelay = 5000):上一次执行完毕时间点之后5秒再执行
@Scheduled(initialDelay=1000, fixedRate=5000):第一次延迟1秒后执行,之后按fixedRate的规则每5秒执行一次
Spring Boot中的Filter自动注入为空
发生这个情况的原因以前在网上看过,模糊记得原因是:tomcat加载顺序依次是监听器,过滤器和servlet。当监听器和过滤器被加载时spring还没启动,因此其实并没有注入,所以为空。解决办法是在监听器的contextInitialized方法开始加上WebApplicationContextUtils.getRequiredWebApplicationContext(servletContextEvent.getServletContext()).getAutowireCapableBeanFactory().autowireBean(this);,过滤器的doFilter方法开始加上SpringBeanAutowiringSupport.processInjectionBasedOnServletContext(this, filterConfig.getServletContext());
commons-codec包
commons-codec包的使用很简单,使用DigestUtils类下的各种静态方法即可,例如DigestUtils.sha256Hex(string)
利用生产者/消费者模式
1 | |
使用Nginx提供文件服务器功能,并实现双机负载均衡
1 | |
参考文献